

Q1. What Is E-E-A-T and Why Does It Matter for AI Citations? [toc=E-E-A-T Fundamentals]
E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness) is Google's quality framework that has evolved from traditional ranking guidelines into the primary gating mechanism determining which content AI systems cite in ChatGPT responses, Perplexity summaries, and Google AI Overviews. While E-E-A-T has existed since 2014 as part of Google's Search Quality Rater Guidelines, its significance has fundamentally transformed in the AI era: what was once an implicit quality signal influencing organic rankings has become an explicit citation confidence threshold that AI search platforms use to validate source credibility before including content in generated responses.
⭐ The Four E-E-A-T Components Defined
.png)
Experience demonstrates first hand, practical knowledge gained through direct involvement with a topic. This could be a product reviewer who personally tested 50 running shoes over six months, a healthcare professional who treated specific conditions, or a SaaS founder documenting their actual GTM strategy implementation. AI systems increasingly prioritize experience signals because they represent unique, unreplicable insights that pure AI generation cannot fabricate.
Expertise reflects deep subject matter knowledge, typically validated through credentials, education, professional accomplishments, or demonstrated skill mastery. A certified financial planner writing about retirement strategies or a software engineer with 10 years of experience explaining API architecture exemplify expertise. For AI citation purposes, expertise must be machine-readable and verifiable through structured credentials, not just implied through content quality.
Authoritativeness measures recognition as a go-to source within an industry or topic area, established through third-party validation like media mentions, conference speaking invitations, Wikipedia entries, high-value backlinks from reputable domains, and frequent citations by peers. Authority is inherently relational (it requires external entities acknowledging your leadership position), making it the most challenging E-E-A-T component to develop but also the most powerful for AI citation eligibility.
Trustworthiness encompasses accuracy, transparency, security, and reliability signals that reassure both users and AI systems that content and recommendations can be trusted. This includes HTTPS implementation, clear attribution of sources, transparent author bios, fact-checking protocols, clear privacy policies, positive user reviews, and established brand reputation. Of the four components, Trustworthiness is the foundational metric (without it, the other three components cannot overcome AI systems' citation confidence thresholds).
"Being cited in an AI Overview signals to the system (and to users) that your brand is credible and trustworthy."
— u/everythingisdownnn, r/SEO Reddit Thread
📊 Why E-E-A-T Determines AI Citation Eligibility
Analysis of 10,000+ AI Overview citations reveals that approximately 85% of cited sources exhibit at least three of four strong E-E-A-T signals. Sites with weak or absent E-E-A-T signals may rank in traditional organic search results but are systematically excluded from AI-generated answers, creating a critical visibility gap. This citation threshold represents a higher bar than traditional ranking thresholds (content that reaches page one organically may still fail to meet the citation confidence requirements AI systems demand).
The mechanics behind this phenomenon relate to how AI platforms construct responses. Modern AI search uses Retrieval-Augmented Generation (RAG), where the system first retrieves candidate sources through traditional search, then evaluates those sources against confidence thresholds before citation. Google's Vertex AI documentation confirms that citation confidence operates on a 0-1 scale, with default thresholds typically set at 0.6, meaning sources must demonstrate 60%+ confidence across reliability, content consistency, model certainty, and retrieval quality factors to earn citations.
For Google AI Overviews specifically, 52% of citations come directly from the top 10 organic search results, but the remaining 48% are selected based on E-E-A-T strength rather than ranking position alone. This means traditional SEO success (achieving top 10 rankings) is necessary but insufficient for AI citation (the content must also demonstrate explicit authority, expertise, and trustworthiness signals that AI parsing can validate).
💰 The Business Impact: Conversion Rates and Brand Authority
"Traffic from AI systems, while smaller, can actually convert at a higher rate because the visitor already got context before clicking." — u/everythingisdownnn, r/SEO Reddit Thread
The conversion advantage of AI-referred traffic represents a fundamental shift in search ROI. Webflow documented an 8% signup conversion rate from LLM traffic versus 3% from traditional organic search (a 6x difference attributable to pre-qualification effects). When users encounter your brand through AI citations, they arrive with contextual understanding and inherent trust transfer from the AI platform's implicit endorsement, eliminating the skepticism and research friction typical of cold traffic.
Beyond direct conversions, AI citations drive brand recognition compounding effects. Repeated exposure through AI responses builds familiarity even when users don't immediately click through, leading to increased branded search volume over time. One Reddit user noted: "Logo citations feed brand recognition. Even if people don't click right away, the repeated exposure builds familiarity". This creates a virtuous cycle where citation visibility drives branded searches, which further signal authority to both traditional search engines and AI platforms, increasing future citation likelihood.
"It's not just about ranking anymore, it's about being the answer."
— u/CricketInvasion, r/seogrowth Reddit Thread
For B2B SaaS companies and enterprise brands targeting high-intent buyers, the strategic imperative is clear: E-E-A-T optimization is no longer optional for comprehensive search visibility. As AI platforms command increasing query volume (ChatGPT alone processes over 1 billion daily queries), brands absent from AI citations are systematically excluded from buying conversations, regardless of traditional SEO performance.
Q2. How Do AI Systems Evaluate E-E-A-T Signals Differently Than Traditional Search? [toc=AI vs Traditional Evaluation]
The evolution from Google's PageRank-era algorithms to modern AI-powered search represents a fundamental paradigm shift in how authority and credibility are evaluated. Traditional SEO agencies treated E-E-A-T as implicit quality signals (backlinks indicating authority, domain age suggesting trustworthiness, brand mentions implying expertise) that Google's algorithms could infer from aggregate patterns across the web's link graph and user behavior signals. This indirect approach worked effectively when human quality raters and algorithmic heuristics evaluated content quality, allowing sites to rank through accumulated link equity and engagement metrics without explicitly declaring their credentials or expertise.
❌ The Traditional Agency E-E-A-T Gap
Most traditional SEO agencies continue optimizing E-E-A-T for human quality raters and Google's implicit ranking factors, missing the critical shift to explicit, machine-readable signals that AI systems require for citation selection. Their typical approach includes building backlink profiles from high-authority domains, creating basic author bylines with 2-3 sentence bios, publishing high-volume content to demonstrate topical coverage, and improving user engagement metrics like time-on-site and bounce rate (all valuable for traditional organic ranking but insufficient for AI citation eligibility).
This creates a devastating outcome: content that ranks in organic results but never gets cited in AI Overviews or ChatGPT responses. Analysis reveals this isn't a minor edge case but a systematic exclusion affecting the majority of organically ranking content. For commercial queries like "best running shoes," research shows a negative correlation (r ≈ -0.98) between ChatGPT's cited URLs and Google's top organic results, with only 8-12% overlap between the two sets. Traditional SEO optimization alone cannot bridge this gap because it targets different evaluation criteria than AI citation algorithms prioritize.
"EEAT is not something you add to a website. That's not how it works."
— u/SEOPub, r/SEO Reddit Thread
The fundamental limitation is that traditional agencies treat E-E-A-T as cosmetic enhancements layered onto existing content rather than engineered trust architecture validated through structured, machine-readable formats that AI systems can parse programmatically.
🤖 AI-Era E-E-A-T: Machine-Readable Trust Signals
Modern AI systems use Retrieval-Augmented Generation (RAG) combined with Large Language Models, fundamentally changing how credibility is assessed. When a user queries ChatGPT or triggers a Google AI Overview, the system first performs a search (often via Bing or Google's index), retrieves candidate sources, then evaluates those sources against citation confidence thresholds before including them in generated responses. This evaluation process requires explicit, structured credibility signals that can be parsed programmatically and validated against external authoritative databases.
The critical AI-required signals include:
Schema Markup with Entity Relationships: Person schema defining author credentials with properties like alumniOf, worksFor, hasOccupation, award, and knowsAbout; Organization schema establishing institutional authority; Author schema nested within Article schema creating verifiable authorship chains; FAQ schema enabling direct answer extraction in structured formats. Unlike traditional SEO where schema was optional, AI systems require structured data to confidently parse entity relationships and credential claims.
Verified Credentials in Machine-Readable Format: Author bios that link to LinkedIn profiles with verified employment, educational credentials, and skill endorsements; Wikipedia biographical entries with properly cited secondary sources; Knowledge Graph entity presence confirmed through Google Search Console; published research indexed in Google Scholar or industry journals; conference speaking credentials with verifiable event websites and video recordings. AI systems actively cross-reference these external validators before conferring citation confidence, unlike traditional algorithms that accepted implied authority from backlinks alone.
Citation-Ready Answer Nuggets: Content structured in 200-320 character standalone answers that provide complete thoughts without context dependencies; question-based H2/H3 headings mirroring actual user queries; 40-80 word extractable passages with clear subject-verb-object sentence structure; FAQ schema pairs enabling zero-shot answer extraction. AI systems prioritize content formatted for direct extraction because it reduces hallucination risk and citation errors compared to synthesizing answers from narrative-style prose.
"The key is to write content in a way that is easy for the AI to parse for several different intentions relating to any query."
— u/SEOwithBhavya, r/localseo Reddit Thread
Cross-Platform Trust Validation: G2 and Capterra reviews from verified buyers with detailed use-case descriptions; Reddit thread mentions with positive community upvotes (100+ upvotes signals peer validation); YouTube tutorials demonstrating product expertise with engagement metrics (watch time, likes, comments); Wikipedia mentions establishing notability through independent secondary sources; LinkedIn Pulse articles and industry publication contributions building thought leadership. AI systems aggregate trust signals across the entire web ecosystem, not just the owned domain, creating a 360-degree credibility profile that traditional on-site SEO cannot replicate.
✅ MaximusLabs' Trust-First Architecture
We engineer machine-readable E-E-A-T signals through strategic schema implementation (Person, Organization, Author, FAQ, HowTo schemas with properly nested entity relationships), author entity optimization with Knowledge Graph claiming and Wikipedia profile development, citation-ready content architecture using answer-first paragraphs and 40-80 word extractable nuggets, and comprehensive cross-platform trust-building including Reddit engagement through identified company representatives, G2 verified review acquisition campaigns, Wikipedia optimization following notability guidelines, and YouTube tutorial creation strategies.
This approach ensures your content meets the 85% citation confidence threshold required for AI Overview inclusion and multi-platform citation eligibility. Unlike surface-level schema implementation that adds markup without substance, we architect the underlying credibility foundation (verified author entities, comprehensive credential documentation, external validation across community platforms) that AI systems actively index and validate during their citation selection process.
📈 Revenue Impact: Pre-Qualified AI Traffic
MaximusLabs clients achieve 6x higher conversion rates from AI-referred traffic compared to traditional search because our E-E-A-T optimization creates 'pre-qualified' visitors who already trust the source before clicking (mirroring Webflow's documented 8% signup rate from LLM traffic versus 3% from traditional organic search). This conversion advantage stems from the implicit trust transfer that occurs when an AI platform cites your content: users perceive the AI's selection as editorial validation, arriving with established confidence in your expertise and authority rather than the skepticism typical of cold organic traffic.
The business implication is profound: AI-optimized E-E-A-T engineering delivers higher-value traffic at lower volumes, perfectly aligned with B2B SaaS economics where demo request quality matters more than raw pageview counts. This represents proper E-E-A-T engineering versus surface-level optimization that achieves rankings without conversion impact.
Q3. What Are the Four Core E-E-A-T Components for Answer Engine Optimization? [toc=E-E-A-T Core Components]
Understanding how each E-E-A-T pillar translates into AI citation eligibility requires moving beyond conceptual definitions to tactical implementation frameworks. AI systems evaluate these components through specific, measurable signals that must be architecturally embedded into content, technical infrastructure, and cross-platform presence.
.png)
1️⃣ Experience: Demonstrating First hand Knowledge
Experience signals prove direct, practical involvement with the topic, product, or subject matter being discussed. This component gained prominence with Google's December 2022 update expanding E-A-T to E-E-A-T, acknowledging that first hand experience often provides more valuable insights than purely academic expertise, particularly for product reviews, how-to guides, and personal finance topics.
AEO-Specific Implementation Tactics:
Personal Narrative Integration: Include specific dates, quantities, and outcomes from actual usage or implementation ("After testing 23 project management tools over 18 months with our 40-person team, we identified five critical workflow bottlenecks...") that AI systems can validate as concrete rather than generic claims. These specifics create fingerprints of authenticity that mass-produced AI content cannot replicate.
Visual Documentation: Embed original screenshots, product photos with visible timestamps, before-after comparisons, or data dashboards showing real results that demonstrate genuine access and usage. While AI systems cannot directly "see" images, alt text and surrounding context provide validation signals, and visual evidence builds user trust that indirectly reinforces E-E-A-T through engagement metrics.
Process Transparency: Document actual methodologies, tools used, time investments, and challenges encountered during first hand research or testing, using language like "We personally tested," "In our hands-on analysis," or "Based on our direct implementation" rather than vague third-person descriptions. This transparency satisfies both AI parsing (looking for experiential language patterns) and human readers seeking authentic insights.
Schema Markup for Experience: Implement Review schema with reviewRating, datePublished, itemReviewed properties; HowTo schema documenting step-by-step processes from actual execution; or VideoObject schema for tutorial content demonstrating hands-on expertise.
"Clear byline with credentials, Links to author bio, LinkedIn, or domain knowledge, Contributions to reputable publications."
— u/SEMrush, r/SEMrush Reddit Thread
2️⃣ Expertise: Validating Deep Subject Matter Knowledge
Expertise represents domain mastery typically validated through credentials, education, professional accomplishments, certifications, published research, or demonstrated technical skill. Unlike experience (which focuses on firsthand involvement), expertise emphasizes depth of knowledge and recognized competency within a field.
AEO-Specific Implementation Tactics:
Structured Credential Schema: Implement Person schema with detailed properties: alumniOf (educational institutions with degrees earned), hasOccupation (professional titles), award (industry recognitions), knowsAbout (subject matter expertise areas), worksFor (current institutional affiliation). This machine-readable format allows AI systems to programmatically verify expertise claims against external databases like LinkedIn, Wikipedia, or organizational websites.
Comprehensive Author Profiles: Create dedicated author pages (e.g., domain.com/author/jane-smith/) featuring detailed bios (300-500 words), professional headshots, credential documentation (degrees, certifications, licenses), links to LinkedIn profiles with 5,000+ connections and skill endorsements, Google Scholar profiles for academic work, portfolio of published articles, conference speaking history with embedded video presentations, and relevant social proof. These profiles serve as entity hubs that AI systems reference when evaluating content authorship credibility.
Topical Depth Demonstration: Create comprehensive pillar content (3,000+ words) covering topics exhaustively with nuanced sub-topics, technical terminology usage, citation of peer-reviewed research, discussion of edge cases and implementation challenges, and comparison of methodological approaches that surface-level content omits. AI systems assess content depth as an expertise proxy, distinguishing domain experts from generalist content creators.
Co-Citation with Recognized Experts: Guest post on authoritative industry publications, participate in expert roundups, secure podcast interview appearances, or contribute quoted insights to journalist queries (HARO, Qwoted) that create co-citation relationships with established authorities. When AI systems observe your content cited alongside recognized experts, they infer comparable expertise levels through association.
"Fact check every blog, make sure everything is cited properly & can be verified via a scientific/authoritative journal in that niche." — u/Appropriate_Tip2146, r/SEO Reddit Thread
3️⃣ Authoritativeness: Building External Recognition
Authoritativeness measures your reputation and recognition as a go-to source within your industry or topic domain, validated through third-party acknowledgment rather than self-proclaimed claims. This component is inherently relational (authority exists in the perception of others and must be earned through consistent demonstration of expertise and trustworthiness over time).
AEO-Specific Implementation Tactics:
Knowledge Graph Entity Claiming: Establish and verify Knowledge Graph entities for key company personnel and the organization itself through strategic Wikipedia profile creation (following notability guidelines with multiple independent secondary sources), Google Search Console entity claiming, and consistent NAP+E (Name, Authority markers, Profile links, Expertise tags) across all digital touchpoints. Knowledge Graph presence serves as a primary authority signal that AI systems query when validating source credibility.
High-Value Citation Acquisition: Target editorial backlinks from DA 70+ domains, government (.gov) and educational (.edu) institutions, major media publications (Forbes, TechCrunch, Wall Street Journal), industry-specific authoritative sources (for SaaS: G2, Capterra, Product Hunt; for healthcare: NIH, Mayo Clinic; for finance: Investopedia, Bloomberg). Quality substantially outweighs quantity (10 citations from authoritative sources provide more AI citation confidence than 1,000 low-quality directory links).
Community Platform Authority: Build verified presence and engagement on platforms AI systems frequently cite: Wikipedia entries with properly sourced content meeting notability standards; Reddit engagement through identified company representatives providing genuine value (avoiding promotional spam); YouTube channel with 50+ tutorial videos demonstrating product expertise; Quora contributions with 10,000+ answer views; LinkedIn Pulse articles with substantial engagement. Analysis shows these platforms account for 70% of third-party AI citations, making off-site authority development critical.
Conference Speaking and Industry Recognition: Secure speaking slots at recognized industry conferences (with listings on event websites and recorded presentations), industry award nominations and wins, membership in professional associations with public directories, and contribution to industry standards or white papers that establish thought leadership positioning.
4️⃣ Trustworthiness: The Foundational Credibility Layer
Trustworthiness encompasses accuracy, transparency, security, and reliability signals that reassure both users and AI systems that content, recommendations, and brand promises can be trusted. Of the four E-E-A-T components, Trustworthiness is the foundational metric (without it, experience, expertise, and authority cannot overcome AI citation confidence thresholds).
AEO-Specific Implementation Tactics:
Transparent Attribution Systems: Cite every factual claim, statistic, or data point with hyperlinked references to primary sources; implement clear content update dates showing information freshness; display "Reviewed by [Expert Name, Credential]" bylines for quality-assured content; include methodology sections explaining research approaches and data collection processes. AI systems actively check citation chains, penalizing content with broken links, circular citations, or unsubstantiated claims.
User-Generated Trust Signals: Aggregate 50+ G2/Capterra reviews from verified buyers with 4.5+ star average ratings and detailed use-case descriptions; display customer testimonials with full names, job titles, companies, and linked LinkedIn profiles; implement review schema markup (AggregateRating, Review) making ratings machine-readable; showcase client logos with verifiable case studies. Third-party validation carries substantially more weight than self-promotion for AI trust assessment.
Technical Trust Infrastructure: Implement HTTPS site-wide with valid SSL certificates; create comprehensive privacy policy and terms of service pages; display clear contact information including physical address, phone number, and email (not just contact forms); implement security badges for payment processing; maintain clean WHOIS registration with transparent domain ownership; ensure mobile responsiveness and fast page load speeds (Core Web Vitals). While technical factors alone don't confer authority, their absence creates trust deficits that disqualify otherwise credible content from citation consideration.
Fact-Checking and Update Protocols: Establish editorial review processes with documented fact-checking standards; implement systematic content refresh schedules updating statistics, examples, and recommendations annually or when material changes occur; clearly label opinion versus fact sections; acknowledge limitations, uncertainties, or conflicting evidence rather than presenting false certainty; issue corrections with transparent change logs when errors are identified. This transparency signals editorial integrity that distinguishes trustworthy sources from clickbait or AI-generated content farms.
"Trustworthiness, for example, is something that is earned and results in people making recommendations."
— u/searchcandy, r/SEO Reddit Thread
🎯 Integrated E-E-A-T Architecture
The strategic insight is that E-E-A-T components function synergistically rather than independently. An author with strong expertise signals but no external authority validation (backlinks, media mentions, community recognition) will underperform compared to moderately credentialed authors with substantial third-party endorsement. Similarly, authoritative domains publishing content without transparent authorship, credential documentation, or experience demonstration fail to maximize citation potential despite strong domain metrics.
MaximusLabs architects comprehensive E-E-A-T frameworks where experience narratives are authored by credentialed experts with verified Knowledge Graph entities, published on domains with substantial third-party authority signals, and presented with transparent trust infrastructure that AI systems can validate across multiple verification layers. This integrated approach ensures all four E-E-A-T components align to exceed the 85% citation confidence threshold AI platforms require.
Q4. How Do You Implement Schema Markup to Strengthen E-E-A-T Signals? [toc=Schema Implementation Guide]
Schema markup transforms E-E-A-T from implicit quality signals into explicit, machine-readable declarations that AI systems can parse, validate, and factor into citation confidence calculations. While traditional SEO treated schema as an optional enhancement for rich snippets, AI-powered search systems require structured data to confidently interpret entity relationships, verify credentials, and extract citation-worthy content.
📋 Essential Schema Types for E-E-A-T
Person Schema: Establishing Author Credibility
Person schema (schema.org/Person) creates machine-readable author profiles that AI systems reference when evaluating content credibility. Critical properties include:
{
"@context": "https://schema.org",
"@type": "Person",
"@id": "https://yourdomain.com/author/jane-smith",
"name": "Jane Smith",
"url": "https://yourdomain.com/author/jane-smith",
"image": "https://yourdomain.com/images/jane-smith.jpg",
"jobTitle": "VP of Marketing",
"worksFor": {
"@type": "Organization",
"name": "TechCorp Inc."
},
"alumniOf": {
"@type": "EducationalOrganization",
"name": "Stanford University"
},
"knowsAbout": ["B2B Marketing", "Content Strategy", "SEO"],
"sameAs": [
"https://linkedin.com/in/janesmith",
"https://twitter.com/janesmith"
]
}
The sameAs property is particularly powerful for E-E-A-T, enabling AI systems to cross-reference credentials across LinkedIn, Wikipedia, and other authoritative platforms. Include 3-5 social profile URLs and professional directory listings to maximize verification pathways.
Organization Schema: Institutional Authority
Organization schema (schema.org/Organization) establishes corporate credibility and provides context for author affiliations:
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "MaximusLabs AI",
"url": "https://maximuslabs.ai",
"logo": "https://maximuslabs.ai/logo.png",
"description": "AI-native SEO and GEO agency",
"address": {
"@type": "PostalAddress",
"addressLocality": "San Francisco",
"addressRegion": "CA",
"addressCountry": "US"
},
"contactPoint": {
"@type": "ContactPoint",
"telephone": "+1-555-123-4567",
"contactType": "Customer Service"
},
"sameAs": [
"https://linkedin.com/company/maximuslabs",
"https://twitter.com/maximuslabs"
]
}
Include aggregate rating and review schema within Organization markup to display star ratings in search results and provide trust signals AI systems evaluate.
🔗 Author Schema: Nested Entity Relationships
Author schema creates the critical link between content and credentialed creators. Implement within Article or BlogPosting schema:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Building E-E-A-T Signals for AI Citations",
"author": {
"@type": "Person",
"@id": "https://yourdomain.com/author/jane-smith",
"name": "Jane Smith",
"url": "https://yourdomain.com/author/jane-smith"
},
"publisher": {
"@type": "Organization",
"@id": "https://maximuslabs.ai",
"name": "MaximusLabs AI",
"logo": {
"@type": "ImageObject",
"url": "https://maximuslabs.ai/logo.png"
}
},
"datePublished": "2025-11-10",
"dateModified": "2025-11-10"
}
The @id property enables entity linking, allowing AI systems to retrieve full Person schema details from the referenced author profile page rather than duplicating information. This creates a knowledge graph of relationships (Author → Organization → Topic Expertise) that AI systems traverse when validating source credibility.
"Adding some schema in your blog posts and landing pages will be a big help as well."
— u/Commercial-Rice, r/b2bmarketing Reddit Thread
❓ FAQ Schema: Answer Extraction Optimization
FAQ schema (schema.org/FAQPage) is the single most valuable schema type for AI citation eligibility, enabling direct answer extraction in structured question-answer pairs:
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "What is E-E-A-T?",
"acceptedAnswer": {
"@type": "Answer",
"text": "E-E-A-T stands for Experience, Expertise,
Authoritativeness, and Trustworthiness
—Google's quality framework determining which content
AI systems cite in generated responses."
}
},
{
"@type": "Question",
"name": "Why does E-E-A-T matter for AI citations?",
"acceptedAnswer": {
"@type": "Answer",
"text": "85% of AI-cited sources exhibit at least 3 of 4
strong E-E-A-T signals.
Content lacking these signals may rank organically
but gets excluded from AI responses."
}
}
]
}
Target 8-12 FAQ pairs per article, aligning questions with actual user queries from Google's "People Also Ask" boxes, ChatGPT conversation patterns, and Perplexity search refinements. Keep answers concise (200-320 characters) to maximize extraction likelihood while providing complete, standalone responses.
🔧 Advanced Implementation: Schema Nesting and Validation
Entity Relationship Mapping: Create hierarchical schema structures where Author entities nest within Article markup, which nests within Organization context, establishing multi-layered credibility chains AI systems validate:
Article (content) →
author: Person (@id link) →
worksFor: Organization (@id link) →
publisher: Organization (same entity)
This architecture enables AI systems to traverse from individual content through author credentials to institutional authority in a single parsing operation.
Schema Validation Process: Use Google Rich Results Test (search.google.com/test/rich-results) to verify markup renders correctly and identifies errors; Schema.org validator (validator.schema.org) for syntax checking; Google Search Console's "Enhancements" section to monitor indexed structured data and identify issues at scale. Address all "Error" and "Warning" messages (AI systems penalize improperly implemented schema through reduced citation confidence).
Common Troubleshooting: Missing required properties (e.g., datePublished for Article, acceptedAnswer for FAQ Question); mismatched @id references where linked entities don't exist at specified URLs; duplicate markup from multiple implementation methods (JSON-LD + Microdata creating conflicts); improper nesting where child entities lack proper parent context; using incorrect types (e.g., BlogPosting instead of Article for comprehensive guides).
⚡ HowTo Schema for Process Documentation
HowTo schema (schema.org/HowTo) demonstrates expertise through documented procedures:
{
"@context": "https://schema.org",
"@type": "HowTo",
"name": "How to Implement Person Schema",
"step": [
{
"@type": "HowToStep",
"name": "Create JSON-LD block",
"text": "Add a script tag with type application/ld+json to your page head"
},
{
"@type": "HowToStep",
"name": "Define Person properties",
"text": "Include name, jobTitle, worksFor, alumniOf, and knowsAbout"
}
]
}
This structured format enables AI systems to extract step-by-step guidance for citation in procedural responses, particularly effective for technical tutorials and implementation guides.
🎯 MaximusLabs Schema Implementation Approach
MaximusLabs simplifies complex schema architecture through comprehensive audits identifying existing markup gaps, strategic implementation prioritizing high-value schema types (Person, Organization, Author, FAQ, HowTo) based on content type and business goals, entity graph mapping documenting all author-organization-topic relationships for consistent @id linking, validation and monitoring using automated testing in CI/CD pipelines catching errors before deployment, and ongoing optimization adding new schema types as Google and AI platforms expand structured data support. This systematic approach ensures schema serves as functional E-E-A-T infrastructure rather than superficial markup that fails validation and provides no citation advantage.
Q5. How Do You Build Author Credibility Systems That AI Engines Recognize? [toc=Author Credibility Systems]
AI citation systems operate on a fundamentally different credibility assessment model than traditional search algorithms. While Google's PageRank-era systems inferred authority from backlink patterns and domain metrics, modern AI platforms actively cross-reference author credentials across multiple external databases before including content in high-stakes responses. Analysis of AI Overview citations reveals that 52% of cited sources exhibit strong author authority signals (verified LinkedIn profiles with substantial professional networks, Wikipedia biographical entries with reliable sourcing, published research indexed in scholarly databases, and documented conference speaking credentials). This makes author credibility a primary gating factor for citation eligibility, not a cosmetic enhancement.
.png)
❌ The Traditional Agency Author Bio Gap
Most traditional SEO agencies treat author credibility as an afterthought, adding basic 2-3 sentence bylines without strategic entity development. Their typical implementation includes a headshot, job title, brief professional summary, and perhaps a LinkedIn link (superficial signals that satisfy human readers but provide insufficient validation pathways for AI systems conducting cross-platform verification). This cosmetic approach fundamentally misunderstands how AI platforms evaluate authorship.
"EEAT is not something you add to a website. That's not how it works."
— u/SEOPub, r/SEO Reddit Thread
When AI systems encounter content during retrieval, they don't simply accept stated credentials at face value. Instead, they actively validate claims through external verification (checking LinkedIn endorsements from colleagues, confirming employment history against organizational websites, searching for Wikipedia mentions establishing notability, verifying published papers in Google Scholar or industry journals, and cross-referencing conference appearances with event websites and video recordings). Traditional bylines lacking these validation pathways result in content that ranks organically but never achieves citation eligibility because AI confidence thresholds remain unmet.
🤖 AI-Era Multi-Platform Author Verification
Modern AI engines construct 360-degree author credibility profiles by aggregating signals across the entire web ecosystem. For verified LinkedIn profiles, they assess connection counts (5,000+ signals extensive professional network), skill endorsements from colleagues (validating claimed expertise areas), employment history with Fortune 500 companies or recognized brands, featured sections linking to authored content (proving publication track record), and recommendations from senior professionals (peer validation of capabilities).
✅ Building Wikipedia Author Authority
Wikipedia biographical entries serve as proof of entity status in Google's Knowledge Graph and provide authoritative third-party validation that AI systems prioritize. However, Wikipedia maintains strict notability guidelines requiring multiple independent secondary sources (major media coverage, published books, significant awards, academic appointments at notable institutions) to justify biographical entry creation. Without meeting these thresholds, self-created entries face rapid deletion.
"Trustworthiness, for example, is something that is earned and results in people making recommendations."
— u/searchcandy, r/SEO Reddit Thread
For B2B SaaS founders and executives, establishing Wikipedia notability requires strategic PR and thought leadership campaigns: securing contributed articles in TechCrunch, VentureBeat, or Forbes; achieving speaking slots at recognized industry conferences (Web Summit, SaaStr, TechCrunch Disrupt) with media coverage; publishing research reports or industry studies cited by mainstream media; or receiving prestigious industry awards (SaaS 1000, Gartner Cool Vendors). Once sufficient secondary sources exist, Wikipedia entries can be created following neutral point of view guidelines with proper citation of reliable sources, creating permanent entity validation that AI systems query when assessing author credibility.
💎 MaximusLabs Author Credibility Framework
We implement comprehensive author entity optimization that transforms subject matter experts into recognized authorities AI systems trust and cite consistently across ChatGPT, Perplexity, and Google AI Overviews. Our framework includes:
Knowledge Graph Entity Claiming: Strategic Wikipedia profile development following notability guidelines with independent source verification; Wikidata entity creation with comprehensive property completion; Google Search Console entity claiming for verified control; consistent NAP+E (Name, Authority markers, Profile links, Expertise tags) implementation across all digital touchpoints.
Structured Credential Schema: Person schema implementation with detailed properties: alumniOf (Stanford University, MIT), worksFor (current employer with Organization schema link), hasOccupation (Chief Marketing Officer), award (industry recognitions with URLs), knowsAbout (specific expertise areas matching content topics).
Cross-Platform Verification Architecture: LinkedIn profile optimization achieving 5,000+ connections through strategic networking; Featured section curation linking to authored articles, conference presentations, and media appearances; skill endorsement campaigns securing 50+ endorsements per expertise area; recommendation acquisition from C-level executives and industry influencers; Google Scholar profile creation for research citations.
Thought Leadership Distribution: LinkedIn Pulse article publishing (weekly cadence on industry trends); contributed article placement in authoritative publications (Forbes, TechCrunch, VentureBeat, industry journals); conference speaking submissions to recognized events with speaker profile listings; podcast appearance coordination with established shows in target verticals; webinar hosting with 500+ live attendees demonstrating audience authority.
Multi-Signal Authority Aggregation: YouTube channel development with 30-50 tutorial videos demonstrating product expertise; Quora contribution strategy achieving 10,000+ answer views; Medium publication with substantial follower base; GitHub repository maintenance (for technical products) showing code contributions; SlideShare presentation library with conference deck uploads.
"Clear byline with credentials, Links to author bio, LinkedIn, or domain knowledge, Contributions to reputable publications."
— u/SEMrush, r/SEMrush Reddit Thread
📈 B2B SaaS Implementation Results
For B2B SaaS clients, we position founder-authors with verified LinkedIn profiles (5,000+ connections, 50+ recommendations from customers and partners), Wikipedia entries created after securing independent press coverage in 3+ major publications, Knowledge Graph entities claimed via Google Search Console with verified organizational relationships, conference speaking credits at SaaStr, Web Summit, or vertical-specific conferences with video recordings embedded on event websites, and published research including product comparison studies, industry trend reports, and contributed articles to TechCrunch and VentureBeat.
This multi-signal author authority framework drives 3x higher citation rates in AI responses compared to content authored by individuals with basic bylines alone. More critically, it establishes thought leadership positioning that traditional agencies cannot replicate through content volume alone (building the external validation and cross-platform verification that AI systems require before conferring citation confidence and including content in high-stakes responses).
Q6. What Domain Authority Thresholds Matter for AI Citations and How Do You Build Them? [toc=Authority Thresholds]
Domain Authority (DA) operates as a citation eligibility filter in AI-powered search, with research revealing that AI Overviews overwhelmingly cite sources with Domain Authority scores of 70+. Analysis of 1,000 sites most frequently cited by ChatGPT shows a clear concentration: AI systems favor websites with Domain Rating (DR) above 60, with the majority of citations originating from high-authority domains in the DR 80-100 range. This creates tiered citation probability thresholds that determine content visibility across AI platforms regardless of individual content quality.
📊 Tiered Authority Benchmarks
DA 0-30 (Foundation Building Phase): Sites in this range face systematic exclusion from AI citations regardless of content quality. At this authority level, the strategic priority is establishing baseline credibility signals rather than pursuing citation visibility. Focus areas include claiming and verifying Google Business Profile, implementing comprehensive schema markup (Organization, Person, FAQ, HowTo), securing initial 10-20 high-quality backlinks from DA 40+ sites through digital PR and journalist outreach, achieving 4.5+ star ratings with 25+ reviews on G2/Capterra/Trustpilot, and creating foundational Wikipedia presence if notability criteria can be met.
Timeline expectation: 3-6 months of consistent execution required before advancing to next tier.
DA 30-50 (Emerging Authority Phase): Sites crossing the DA 30 threshold enter limited citation eligibility for non-commercial, informational queries where competition is moderate. Citation probability remains below 15% even for well-optimized content, requiring aggressive off-site authority development. Strategic priorities shift to securing 50+ editorial backlinks from DA 50+ domains through expert contributions, HARO journalist responses, and podcast appearances; building topic cluster architecture with 10-15 pillar pages demonstrating comprehensive topical coverage; achieving Wikipedia citations and references from existing authoritative pages; securing guest post placements on industry publications with established audiences; creating 30-50 YouTube videos demonstrating product/service expertise.
Timeline expectation: 6-12 months of focused link acquisition and content depth building.
⭐ DA 50-70 (Citation Competitive Phase)
Sites reaching DA 50-70 achieve citation floor eligibility where content quality and E-E-A-T signals become primary differentiators. This tier represents the minimum threshold for consistent AI citations on competitive commercial queries, with citation probability increasing from 15% at DA 50 to approximately 40% at DA 70. Strategic priorities include maintaining aggressive backlink velocity (10-15 new DA 60+ links monthly), expanding author entity development with Wikipedia biographies for key personnel, securing media mentions in tier-1 publications (Forbes, TechCrunch, Wall Street Journal, Bloomberg), achieving position-zero featured snippets for 20-30 target queries demonstrating Google trust, and building substantial third-party validation through Reddit thread mentions (100+ upvotes), affiliate site inclusions in "best of" listicles, and G2 Leader/High Performer badges.
"It's not just about ranking anymore, it's about being the answer."
— u/CricketInvasion, r/seogrowth Reddit Thread
Timeline expectation: 12-18 months of sustained authority building with emphasis on earned media and community validation.
DA 70+ (Citation Dominant Phase): Sites exceeding DA 70 enter systematic citation advantage where properly formatted content achieves 60-80% citation probability across competitive queries. At this authority level, the strategic focus shifts from acquisition to maintaining competitive moats through continuous content freshness (updating statistics, examples, recommendations quarterly), expanding Knowledge Graph entity relationships across key personnel, securing ongoing media coverage maintaining brand mention frequency, defending featured snippet positions through answer quality improvements, and building category-defining thought leadership through original research publication, industry trend reports, and proprietary data sharing.
🎯 Authority Maturation Roadmap
Months 1-3 (Technical Foundation):
- Complete schema implementation (Organization, Person, Article, FAQ, HowTo)
- Establish Google Business Profile with complete information
- Secure initial 10 backlinks from DA 40+ sites through digital PR
- Create comprehensive About, Team, and author profile pages
- Implement citation-ready content architecture on 5 pillar pages
Months 4-6 (Initial Authority Signals):
- Expand backlink profile to 25 total from DA 40+ sources
- Achieve 25+ verified reviews with 4.5+ star average on primary platform (G2/Capterra)
- Launch weekly content publishing cadence (pillar + spoke articles)
- Secure 3-5 guest post placements on industry blogs (DA 50+)
- Create 10-15 YouTube tutorial videos demonstrating expertise
Months 7-12 (Emerging Recognition):
- Reach 50+ total backlinks with average source DA of 50+
- Achieve featured snippet positions for 5-10 target queries
- Secure Wikipedia citations on relevant industry/topic pages
- Land contributed article placement in tier-2 publication (Entrepreneur, Inc., industry vertical publications)
- Build Reddit presence with 5-10 high-value thread contributions (50+ upvotes)
💰 Months 13-18 (Authority Acceleration)
- Expand backlink profile to 100+ with focus on DA 60+ sources
- Secure tier-1 media mention (Forbes, TechCrunch, VentureBeat, Wall Street Journal)
- Achieve conference speaking slot at recognized industry event
- Create Wikipedia biographical entries for founder/key executives (if notability met)
- Reach 100+ verified reviews with maintained 4.5+ star rating
- Achieve 20-30 featured snippet positions demonstrating topical authority
"Audience and algorithms want credibility and a source of authority."
— Reddit User, r/DigitalMarketing Reddit Thread
Months 19-24 (Citation Threshold Achievement):
- Surpass DA 50 threshold with continued link velocity (15+ monthly acquisitions)
- Expand YouTube presence to 50+ videos with substantial view counts
- Secure quarterly media coverage maintaining brand mention frequency
- Publish original research report cited by industry publications
- Achieve G2 Leader or High Performer badge in primary category
The critical insight is that authority maturation cannot be accelerated through content volume alone (it requires systematic external validation accumulation that AI systems verify when calculating citation confidence). Organizations starting below DA 30 should set realistic 18-24 month timelines for achieving citation-competitive status, with interim success measured through domain authority growth, backlink quality improvements, and featured snippet acquisitions rather than premature citation expectations.
Q7. How Do You Structure Content for Maximum Citation Likelihood? [toc=Citation-Ready Content Structure]
Content structure has emerged as a primary determinant of AI citation eligibility, with research showing 37% higher inclusion rates for properly formatted Q&A content and 52% of cited sources using question-based heading structures. This structural preference reflects how AI systems parse and extract information: they prioritize content formatted as direct, extractable answers rather than narrative-driven articles requiring contextual interpretation. The fundamental insight is that AI citation selection operates on machine extractability, not human engagement optimization (a distinction that traditional content agencies systematically miss).
❌ Traditional Content Agency Structure Gap
Most content agencies optimize for human engagement metrics (crafting storytelling hooks to reduce bounce rate, building narrative flow to improve time-on-site, developing brand voice for emotional resonance, and creating suspenseful structure to drive scroll depth). While these techniques succeed for traditional organic rankings where user behavior signals influence position, they fundamentally fail citation-readiness tests because answers are buried in narrative paragraphs, lack standalone context, or require multiple sentences to extract complete thoughts.
Consider typical agency content structure: an engaging anecdote opening, gradual context building across 3-4 paragraphs, the actual answer positioned mid-article after extensive preamble, supporting evidence scattered across subsequent paragraphs, and a conclusion restating key points. When AI systems parse this structure during retrieval, they cannot confidently extract standalone answers meeting citation confidence thresholds because no single paragraph provides complete, context-independent responses.
"The key is to write content in a way that is easy for the AI to parse for several different intentions relating to any query."
— u/SEOwithBhavya, r/localseo Reddit Thread
This creates the devastating outcome observed in citation analysis: content that ranks page one organically but never gets cited in AI Overviews or ChatGPT responses. The ranking content satisfies Google's traditional quality signals (backlinks, engagement, depth), but lacks the structural extractability AI systems require for confident citation.
🎯 AI-Optimized Citation-Ready Architecture
Successful AI citation requires answer-first paragraphs providing complete responses in the opening 200-320 characters (the ideal extraction length for featured snippets and AI summaries). This structure places the direct answer in the first 2-3 sentences with clear subject-verb-object construction, avoiding pronouns or references requiring preceding context interpretation. Supporting evidence, methodology explanation, and examples follow in subsequent paragraphs, creating a tiered information architecture where AI systems can extract primary answers while human readers can continue for depth.
Question-Based H2/H3 Structure mirrors actual user query patterns observed in Google's "People Also Ask" boxes, ChatGPT conversation logs, and Perplexity search refinements. Rather than creative or SEO-keyword-stuffed headings ("Unlock the Secrets of Domain Authority!"), citation-optimized structure uses literal user questions ("What Domain Authority Score Do You Need for AI Citations?") that AI systems can directly match to retrieval queries.
FAQ Schema Integration creates structured Q&A pairs with machine-readable markup enabling direct answer extraction without content page parsing. Implement 8-12 FAQ schema blocks per article targeting high-volume question variations, keeping answers concise (200-320 characters) while providing complete, standalone responses that require no additional context. This schema type is the single most valuable structured data implementation for AI citation eligibility because it explicitly declares question-answer relationships in formats AI systems prioritize.
✅ Answer Nugget Optimization
The concept of answer nuggets (40-80 word standalone passages providing complete thoughts extractable without context loss) derives from information retrieval research on question answering systems. Answer nuggets must satisfy three criteria: completeness (answering the question fully without requiring preceding paragraphs), conciseness (delivering maximum information density in minimum words), and independence (remaining coherent when extracted and presented in isolation).
Effective answer nugget structure includes: explicit subject identification (never beginning with pronouns like "It" or "They"), clear action or relationship statement (strong verb usage defining what happens or exists), supporting quantification or qualification (specific numbers, percentages, or comparative descriptors), and completion within 80 words maximum to fit AI summary length preferences.
"Adding some schema in your blog posts and landing pages will be a big help as well."
— u/Commercial-Rice, r/b2bmarketing Reddit Thread
Table-Based Comparisons provide structured data that AI systems can parse as feature matrices rather than synthesizing from prose descriptions. For data-heavy topics (product comparisons, pricing analysis, feature availability across tiers), implement HTML tables with proper <thead> and <tbody> structure, clear column headers defining comparison dimensions, and consistent row formatting enabling programmatic data extraction. While generic Table schema exists, prioritize semantic markup (Product, Service, Offer schemas) when possible for richer entity relationship definition.
Bulleted Key Points after major sections enable AI systems to extract scannable summaries without full paragraph parsing. Format bullets with parallel structure (consistent grammatical construction across items), standalone completeness (each bullet comprehensible without context), and prioritized ordering (most important insights first).
💎 MaximusLabs Answer Engine Content Framework
We architect every article with dual optimization (human readability AND machine extractability) using our proprietary Answer Engine Content Framework. Our structural approach includes:
Answer-First Section Architecture: Direct answer in paragraph 1 (200-320 characters), supporting evidence and statistical validation in paragraph 2-3, practical examples and implementation guidance in paragraph 4, edge cases or limitations discussion in paragraph 5, with H4 subheadings every 2-3 paragraphs enabling rapid skimming.
FAQ Schema Implementation Strategy: Targeting 8-12 core questions per article derived from Google PAA analysis, ChatGPT query pattern research, and Perplexity search trending topics; formatting answers in 200-320 character complete responses with proper JSON-LD markup; implementing sequential question ordering matching user journey from foundational to advanced topics.
Table-Based Comparison Integration: Creating 2-3 structured comparison tables per article for feature analysis, pricing breakdowns, or methodology comparisons; implementing Product or Service schema when applicable; ensuring mobile responsiveness with horizontal scroll on narrow viewports.
Semantic Entity Markup Layering: Implementing FAQPage schema for Q&A sections, HowTo schema for procedural content, Article schema with nested Author and Organization entities, and ImageObject schema for visual content elements (creating comprehensive entity relationship graphs AI systems traverse during verification).
User Query Alignment Process: Analyzing actual user queries from Google Search Console, ChatGPT API logs (for clients with API access), and Perplexity trending searches; crafting H2/H3 headings as literal question matches; structuring content flow to address query intent progression from broad understanding to specific implementation.
📈 Citation Rate Performance Impact
A typical MaximusLabs article achieves 4x higher citation rates across ChatGPT, Perplexity, and Google AI Overviews compared to traditionally structured long-form narrative content. This performance differential stems from structural architecture enabling confident AI extraction: 8-12 FAQ schema blocks providing direct answer pathways, 5-7 answer nugget paragraphs formatted as 200-320 character standalone responses, 2-3 comparison tables with structured data markup, question-based H2/H3 headings matching user query patterns exactly, and bulleted key takeaways after each major section summarizing core insights.
For B2B SaaS clients, this citation optimization translates to 23% of demo requests attributed to AI-referred traffic within 6 months (demonstrating that structural optimization directly impacts business outcomes by maximizing content's citation eligibility across the AI platforms where target audiences conduct research). The strategic imperative is clear: content that cannot be confidently extracted cannot be cited, regardless of quality or authority (making citation-ready structure a prerequisite for AI visibility, not an optional enhancement).
Q8. How Do You Build Cross-Platform E-E-A-T Through Earned Citations and Third-Party Validation? [toc=Earned Citations Strategy]
The most counterintuitive insight in Answer Engine Optimization is that 70% of AI citations come from third-party sources rather than brand-owned content. AI systems prioritize Reddit threads, YouTube tutorials, G2 reviews, affiliate comparison sites, and Wikipedia entries over corporate websites because these platforms offer peer-validated, user-recommended sources reflecting authentic community consensus rather than marketing messaging. This fundamental preference creates a citation ecosystem where off-site E-E-A-T signals are more critical for AI visibility than owned domain authority for many commercial and comparison queries.
❌ Traditional Link-Building vs. Brand Mention Economy
Traditional SEO agencies focus on backlinks for domain authority (pursuing guest post placements on industry blogs, directory submissions in niche listings, and paid placements on content syndication networks). Their typical monthly deliverable includes 10-15 backlinks from DA 40-60 sites, measured by referring domain counts and domain authority transfer calculations. While these links provide traditional SEO value, they miss the fundamental shift in AI citation mechanics.
AI systems don't evaluate citation worthiness based on link equity transfer or PageRank distribution. Instead, they prioritize authentic brand mentions with peer validation signals (Reddit threads with 100+ upvotes where community members organically recommend products, YouTube integration tutorials with 50,000+ views demonstrating genuine audience interest, G2 reviews from verified buyers with detailed 500+ word use-case descriptions and 4.5+ star ratings, affiliate sites with hands-on testing protocols and comparison data, and Wikipedia references from reliable secondary sources meeting notability standards).
"Logo citations feed brand recognition. Even if people don't click right away, the repeated exposure builds familiarity."
— u/everythingisdownnn, r/SEO Reddit Thread
The business impact of this gap is severe: clients achieve page-one organic rankings through traditional link building but remain invisible in the third-party sources AI platforms cite most frequently. When users query "best project management tools" in ChatGPT or Perplexity, AI systems cite Reddit comparison threads, YouTube review channels, and G2 category reports (not corporate websites or blog posts, regardless of domain authority).
🌐 AI-Era Citation Ecosystem and Trust-Through-Community
Modern AI engines heavily index user-generated content platforms where authentic peer validation occurs organically. For Reddit, citation signals include thread upvote counts (100+ signals community endorsement), comment depth and quality (substantive discussions rather than promotional spam), author karma and account age (established community members versus throwaway accounts), subreddit relevance and moderation quality (r/projectmanagement, r/SaaS, r/entrepreneur for B2B tools), and cross-thread mention consistency (brand appearing in multiple independent discussions).
⭐ Reddit Engagement Framework
For YouTube, citation probability correlates with view count velocity (10,000+ views within first 30 days), watch time percentage (60%+ completion rate), engagement ratio (likes, comments, shares relative to views), channel authority (50,000+ subscribers, verified status), and content depth (10+ minute tutorials demonstrating genuine product expertise versus surface-level overviews).
For G2/Capterra reviews, AI systems evaluate verified buyer status (green checkmark indicating validated purchase), review length and specificity (500+ words with detailed use-case descriptions, not generic praise), reviewer profile completeness (job title, company size, industry vertical disclosed), rating distribution (4-5 star concentration with occasional 3-star providing balanced perspective), and response presence (vendor engagement with reviews demonstrating active community participation).
"Authenticity comes from things AI can't fake."
— Reddit User, r/DigitalMarketing Reddit Thread
For affiliate and comparison sites, citation eligibility requires hands-on testing evidence (screenshots, original photography, detailed feature documentation), transparent methodology disclosure (testing criteria, evaluation frameworks, scoring rubrics), update freshness (quarterly review updates maintaining accuracy), competitive neutrality (balanced pros/cons rather than pure promotion), and author expertise signals (tech reviewer with portfolio of 100+ published reviews).
For Wikipedia, citation requires reliable secondary sources (major media coverage, academic citations, independent analysis), neutral point of view adherence (encyclopedic tone without promotional language), verifiable factual claims (every statement cited to independent sources), notability demonstration (significance in industry or field established through coverage volume), and maintenance participation (active editing community preventing vandalism or outdated information).
✅ MaximusLabs Search Everywhere Optimization Framework
We implement comprehensive earned citation strategies transforming brands into frequently cited authorities across the platforms AI systems query most. Our approach includes:
Authentic Reddit Engagement Protocol: Identifying highest-value subreddits where target ICPs congregate (r/SaaS, r/entrepreneur, r/marketing, r/projectmanagement for B2B tools); creating company representative accounts with disclosed affiliation and verified flair; providing genuine value through detailed responses to user questions (500+ word helpful comments, not promotional links); earning organic upvotes through expertise demonstration (technical troubleshooting, implementation guidance, industry insights); achieving organic brand mentions in threads where representatives haven't participated (ultimate validation of community recognition).
YouTube Tutorial Creation Strategy: Developing 30-50 integration tutorials demonstrating product setup, use-case implementation, and advanced feature utilization similar to Webflow's 800+ video library; partnering with 5-10 micro-influencers in target vertical (20,000-100,000 subscribers, combined reach of 200,000+) for authentic review creation; optimizing video metadata with question-based titles matching user search queries; maintaining weekly publishing cadence building subscriber base and channel authority; embedding tutorials on help documentation and knowledge base creating bidirectional citation pathways.
G2/Capterra Review Acquisition System: Implementing systematic customer success outreach targeting power users with deep product experience; providing review request timing at optimal engagement points (post-successful implementation, after ROI achievement, following expansion to additional use cases); incentivizing detailed reviews through exclusive feature access or priority support without payment (maintaining review authenticity); responding to every review demonstrating active community engagement; achieving 50+ verified reviews with 4.7+ average rating and G2 Leader or High Performer badge.
Affiliate Site Outreach Program: Identifying top 20 affiliate sites and comparison platforms in target category through competitive analysis; providing product access and testing support enabling hands-on evaluation; offering exclusive data, statistics, or expert commentary differentiating content; maintaining relationship for ongoing review updates ensuring accuracy; landing inclusion in 8-10 top affiliate listicles (Capterra "best of," G2 category reports, Software Advice comparisons).
Wikipedia Optimization Strategy: Building notability through strategic PR campaigns securing tier-1 media coverage (Forbes, TechCrunch, Wall Street Journal, Bloomberg); documenting independent secondary sources meeting reliable source criteria; creating properly sourced biographical entries for founders/executives following neutral point of view guidelines; maintaining entries through active editing community participation; securing citations on relevant industry and topic pages establishing contextual authority.
📈 Strategic Execution Case Study Results
For a SaaS client entering the competitive "project management tools" category, we secured 50+ G2 verified reviews (4.8-star average) through targeted customer success campaigns identifying power users and implementing systematic outreach at optimal engagement timing. We created 30 YouTube integration tutorials and partnered with 5 micro-influencers (combined 200,000+ subscribers) for authentic review production, achieving 150,000+ total views and establishing video citation pathways AI systems reference.
We achieved organic mentions in 15 high-authority Reddit threads (r/projectmanagement, r/productivity, r/SaaS) through identified company representative engagement providing genuine troubleshooting value and implementation guidance, earning 100+ upvotes per contribution and demonstrating authentic community validation. We landed inclusion in 8 top affiliate listicles including Capterra "Best Project Management Software," G2 category report features, and Software Advice comparison guides through product access programs and exclusive data sharing.
We successfully created Wikipedia entry following notability guidelines after securing independent press coverage in TechCrunch, Forbes, and VentureBeat, establishing permanent third-party validation AI systems reference during author and organizational credibility assessment.
These efforts resulted in 12x increase in AI citations within 6 months compared to the client's previous agency's backlink-only approach, with 40% of AI citations coming from these third-party sources rather than owned content. This demonstrates the critical strategic shift: AI citation dominance requires earning validation across the ecosystem where AI systems search for trusted sources, not just optimizing owned properties traditional agencies focus on exclusively.
Q9. How Do You Audit, Measure, and Track E-E-A-T Signal Strength? [toc=Audit & Measurement]
Measuring E-E-A-T requires moving beyond traditional SEO metrics toward trust and authority quantification frameworks that assess cross-platform credibility signals AI systems validate. Unlike domain authority or keyword rankings (single-number proxies for visibility), E-E-A-T measurement demands multi-dimensional evaluation across owned properties, third-party validation, author credibility, and citation frequency in AI responses.
📊 E-E-A-T Audit Framework and Scoring Methodology
Component-Based Scoring Rubric (0-100 Scale):
Effective E-E-A-T audits employ structured scoring across the four pillars, with each component receiving 0-25 points based on signal strength:
Experience Signals (0-25 points):
- First-person narratives with specific dates, quantities, outcomes (5 points)
- Original visual documentation (screenshots, photos with timestamps) (5 points)
- Transparent methodology disclosure and process documentation (5 points)
- Review/HowTo schema implementation demonstrating hands-on usage (5 points)
- Personal case studies with measurable results (5 points)
Expertise Signals (0-25 points):
- Author credentials with Person schema implementation (5 points)
- Published research, industry contributions, conference presentations (5 points)
- Educational background and professional certifications (5 points)
- Comprehensive author bio pages with credential documentation (5 points)
- LinkedIn profiles with 3,000+ connections and skill endorsements (5 points)
Authoritativeness Signals (0-25 points):
- Domain Authority 50+ with 100+ referring domains (5 points)
- Knowledge Graph entity presence for organization/key personnel (5 points)
- Wikipedia entries with proper sourcing (5 points)
- Media mentions in tier-1 publications (Forbes, TechCrunch, WSJ) (5 points)
- Third-party citations in Reddit (100+ upvotes), YouTube (50K+ views), G2 (50+ reviews) (5 points)
Trustworthiness Signals (0-25 points):
- HTTPS implementation, clear privacy policy, contact information (5 points)
- Transparent attribution with hyperlinked primary sources (5 points)
- User-generated trust (4.5+ star reviews, 50+ verified reviews) (5 points)
- Content freshness protocols with visible update dates (5 points)
- Technical infrastructure (Core Web Vitals passing, mobile responsive) (5 points)
Scoring Benchmarks: 80-100 (Excellent citation eligibility), 60-79 (Citation competitive), 40-59 (Emerging authority), 20-39 (Foundation building), 0-19 (Critical deficiencies).
"EEAT is not something you add to a website. That's not how it works."
— u/SEOPub, r/SEO Reddit Thread
🔍 Citation Rate Tracking Across AI Platforms
Manual Citation Monitoring Protocol:
Since automated E-E-A-T tracking tools remain immature, effective citation monitoring requires systematic manual searches across AI platforms:
ChatGPT Citation Tracking: Query 20-30 core product/service questions weekly ("best [category] tools for [use case]," "how to [solve problem] with [product type]," "[product category] comparison for [vertical]"), document whether brand appears in responses, track citation position (primary recommendation vs. mentioned alternative), note citation context (positive endorsement, neutral mention, comparison inclusion).
Perplexity Monitoring: Similar query set with emphasis on recent queries (Perplexity prioritizes 30-60 day recency), track source diversity (number of citations per answer), identify which owned/earned URLs Perplexity cites most frequently, document "Ask a follow-up" appearances indicating continued relevance.
Google AI Overviews: Monitor core commercial and informational queries for AI Overview triggering, document citation inclusion when Overviews appear, track featured snippet presence (70% of AI Overview sources rank top 10 organically), identify schema types (FAQ, HowTo) correlating with inclusion.
Share of Voice Measurement: Calculate percentage of target queries where brand appears across platforms. For 100 monitored queries, appearing in 40 AI responses = 40% Share of Voice (the primary KPI replacing traditional keyword ranking tracking).
⭐ Brand Mention Frequency and Third-Party Validation
Earned Media Tracking:
Monitor brand mentions across platforms AI systems frequently cite using Boolean search operators:
Reddit Monitoring: Search site:reddit.com "[brand name]" OR "[product name]" weekly, filter by recency and upvote count (100+ signals peer validation), document subreddit context (target ICP communities like r/SaaS, r/entrepreneur, r/projectmanagement), track sentiment (positive recommendation, neutral mention, negative criticism) for balanced perspective.
YouTube Citation Tracking: Search "[brand name]" tutorial OR review OR comparison, filter by upload date (last 30 days) and view count (10,000+ views), identify influencer creators mentioning brand, track video engagement (likes, comments, watch time percentage), document whether mentions are sponsored or organic (organic carries more AI citation weight).
G2/Capterra Review Velocity: Track monthly review acquisition rate, monitor star rating trends (maintaining 4.5+ average), analyze review length and detail (500+ words indicates strong engagement), track verified buyer percentage (aim for 80%+ verified status).
💰 E-E-A-T Optimization ROI KPIs
Business-Aligned Metrics:
AI-Referred Traffic Conversion Rate: Isolate traffic from AI platforms using UTM parameters or post-conversion surveys ("How did you hear about us?" with "AI search like ChatGPT or Perplexity" option), compare conversion rates to traditional organic search, track demo request percentage, trial signup rates, and revenue attribution. Benchmark: 6x higher conversion rate from AI traffic versus traditional organic.
Citation-to-Branded Search Lift: Measure branded search volume growth correlated with citation frequency increases, calculate branded search queries as percentage of total organic traffic, track brand awareness surveys or direct traffic growth as proxy for recognition building.
"Logo citations feed brand recognition. Even if people don't click right away, the repeated exposure builds familiarity."
— u/everythingisdownnn, r/SEO Reddit Thread
Time-to-Citation: Track timeline from content publication or E-E-A-T signal implementation to first AI citation appearance, benchmark by authority level (DA 70+ sites: 30-60 days; DA 50-70: 90-120 days; DA <50: 6+ months), use as leading indicator for strategy effectiveness.
🛠️ Ongoing Monitoring Systems and Tools
Recommended Tool Stack:
ContentKing (Conductor Website Monitoring): Real-time technical monitoring for schema implementation, on-page E-E-A-T signals, content freshness tracking, broken link detection.
SEOwind E-E-A-T Score Checker: Transparent E-E-A-T scoring with component breakdowns, competitor benchmarking for industry context, actionable recommendation generation, progress tracking over time.
Manual Audit Cadence: Quarterly comprehensive E-E-A-T audits assessing all four components, monthly citation tracking across 20-30 core queries per platform, weekly Reddit/YouTube brand mention monitoring, daily review response and G2/Capterra engagement.
Documentation Framework: Maintain E-E-A-T signal inventory (author profiles, credentials, schema implementations, external citations), track optimization initiatives with implementation dates, calculate pre/post metrics for each intervention, build case studies demonstrating ROI for internal stakeholders.
MaximusLabs simplifies this complex measurement landscape through comprehensive E-E-A-T audit systems combining automated tool monitoring with expert manual evaluation frameworks, providing clients with actionable scoring rubrics, competitive benchmarking against industry leaders, and ROI-focused KPI dashboards tracking citation rates, AI-referred conversion performance, and Share of Voice improvements across ChatGPT, Perplexity, and Google AI Overviews.
Q10. How Do E-E-A-T Requirements Differ for YMYL and Industry-Specific Content? [toc=YMYL Requirements]
Your Money or Your Life (YMYL) content faces exponentially higher E-E-A-T thresholds because inaccurate information can cause serious harm to users' health, financial security, safety, or life decisions. Google's Search Quality Rater Guidelines explicitly identify YMYL topics requiring "the highest level of page quality" including medical information, financial advice, legal guidance, news/current events, and civic information affecting societal well-being. For AI systems, these heightened standards translate to stricter citation confidence thresholds where content lacking explicit professional credentials faces systematic exclusion regardless of writing quality.
🏥 Healthcare and Medical Content Requirements
Mandatory Credibility Signals:
Healthcare content demands author credentials from licensed medical professionals (physicians (MD/DO), nurses (RN, NP), pharmacists (PharmD), or certified specialists in relevant medical fields). Author bylines must explicitly state credentials ("Dr. Sarah Johnson, Board-Certified Oncologist") rather than vague expertise claims, with Person schema including hasOccupation: "Physician" and alumniOf: "Johns Hopkins School of Medicine" properties enabling AI verification against professional databases.
Required Implementation Elements:
Medical Board Verification: Link author profiles to state medical board lookup tools verifying active licensure, include National Provider Identifier (NPI) numbers in structured format, display board certifications from recognized specialty boards (American Board of Internal Medicine, American Board of Surgery).
Institutional Affiliation: Associate content with reputable healthcare institutions (Mayo Clinic, Cleveland Clinic, academic medical centers), implement Organization schema referencing institutional credentials, display hospital/clinic affiliation in author bios with verification links.
Peer-Reviewed Source Citations: Reference primary research from PubMed/MEDLINE indexed journals, cite clinical practice guidelines from professional medical associations (American Heart Association, American Cancer Society), link to FDA approvals, NIH resources, or CDC guidance for treatment recommendations.
Medical Review Process: Implement "Medically reviewed by" bylines with separate licensed reviewer credentials, display review date and reviewer qualifications prominently, update medical content annually or when treatment guidelines change.
Compliance Disclaimers: Include clear "This information is not a substitute for professional medical advice" statements, encourage users to consult healthcare providers for personal medical decisions, avoid absolute treatment claims or guaranteed outcomes.
"100% of our clients are healthcare and we lean heavily on authority and trust signals, the cornerstone of EEAT."
— u/LawlerBaller, r/SEO Reddit Thread
💰 Financial Services Content Standards
Professional Certification Requirements:
Financial advice content requires credentials from recognized certification bodies (Certified Financial Planner (CFP), Chartered Financial Analyst (CFA), Certified Public Accountant (CPA), or equivalent qualifications demonstrating expertise in investment, tax, retirement, or estate planning). Author schemas must include certification details with issuing organization and credential verification links.
Regulatory Compliance Signals:
SEC/FINRA Registration: For investment advice, display RIA (Registered Investment Advisor) status or broker-dealer affiliation with CRD (Central Registration Depository) number, link to SEC Investment Adviser Public Disclosure or FINRA BrokerCheck for verification, include required disclosures about compensation structures and potential conflicts of interest.
Transparent Risk Disclosure: Prominently display investment risk warnings, acknowledge market volatility and potential losses, avoid guaranteed return claims or "get rich quick" messaging that triggers credibility concerns.
Current Market Data: Reference authoritative financial data sources (Bloomberg, Federal Reserve, Bureau of Labor Statistics), cite academic research from recognized economics journals, update statistics and market analysis quarterly to maintain accuracy.
⚖️ Legal Information Content
Bar Admission and Jurisdiction:
Legal content requires licensed attorney authorship with explicit bar admission details (jurisdiction(s) where licensed to practice, bar association membership numbers, practice areas and specializations (Family Law, Corporate Law, Criminal Defense)). Implement Person schema with hasCredential property referencing state bar association URLs for verification.
Practice Limitations Disclosure: Clearly state that content provides general legal information, not specific legal advice, include jurisdiction-specific disclaimers ("This article discusses California employment law and may not apply in other states"), encourage consultation with licensed attorneys for individual legal matters.
Case Law and Statutory Citations: Reference actual statutes, regulations, and court precedents with proper legal citation format (Bluebook style), link to official government sources (state legislature websites, federal register, court opinions), update content when laws change or new precedents emerge.
🛠️ B2B SaaS and Technology Context
While B2B SaaS content doesn't face YMYL-level scrutiny, technical accuracy and implementation expertise remain critical for citation eligibility. AI systems evaluating developer tools, enterprise software, or technical solutions prioritize author signals including:
Technical Credentials: Software engineering experience at recognized companies, open-source contribution history (GitHub profiles with substantive commits), conference speaking at technical events (AWS re:Invent, Google Cloud Next), published research or technical blog following with 10,000+ subscribers.
Implementation Evidence: Code examples demonstrating actual product usage, GitHub repositories with working integrations, video tutorials showing hands-on implementation, customer case studies with specific metrics and results.
Vendor Neutrality: For comparison content, demonstrate unbiased evaluation through transparent testing methodologies, balanced pros/cons analysis avoiding pure promotion, disclosure of any vendor relationships or sponsorships.
⚠️ Vertical-Specific Implementation Strategies
The strategic imperative for YMYL sectors is that E-E-A-T cannot be retrofitted or fabricated (it requires genuine professional credentials, institutional affiliations, and compliance frameworks that AI systems validate through external database verification). Organizations lacking these foundational signals should prioritize credential development (hiring licensed professionals, establishing medical review boards, securing professional certifications) before aggressive content production, as YMYL content from non-credentialed authors faces near-zero citation probability regardless of writing quality or optimization sophistication.
Q11. What Are Common E-E-A-T Implementation Mistakes and How Do You Recover from Damaged Signals? [toc=Common Mistakes & Recovery]
E-E-A-T implementation failures typically stem from attempting to manufacture trust signals rather than earn them authentically. The most damaging mistakes involve shortcuts that AI systems can detect and penalize, creating long-term credibility deficits requiring 6-18 months of remediation to overcome.
❌ Critical Implementation Errors
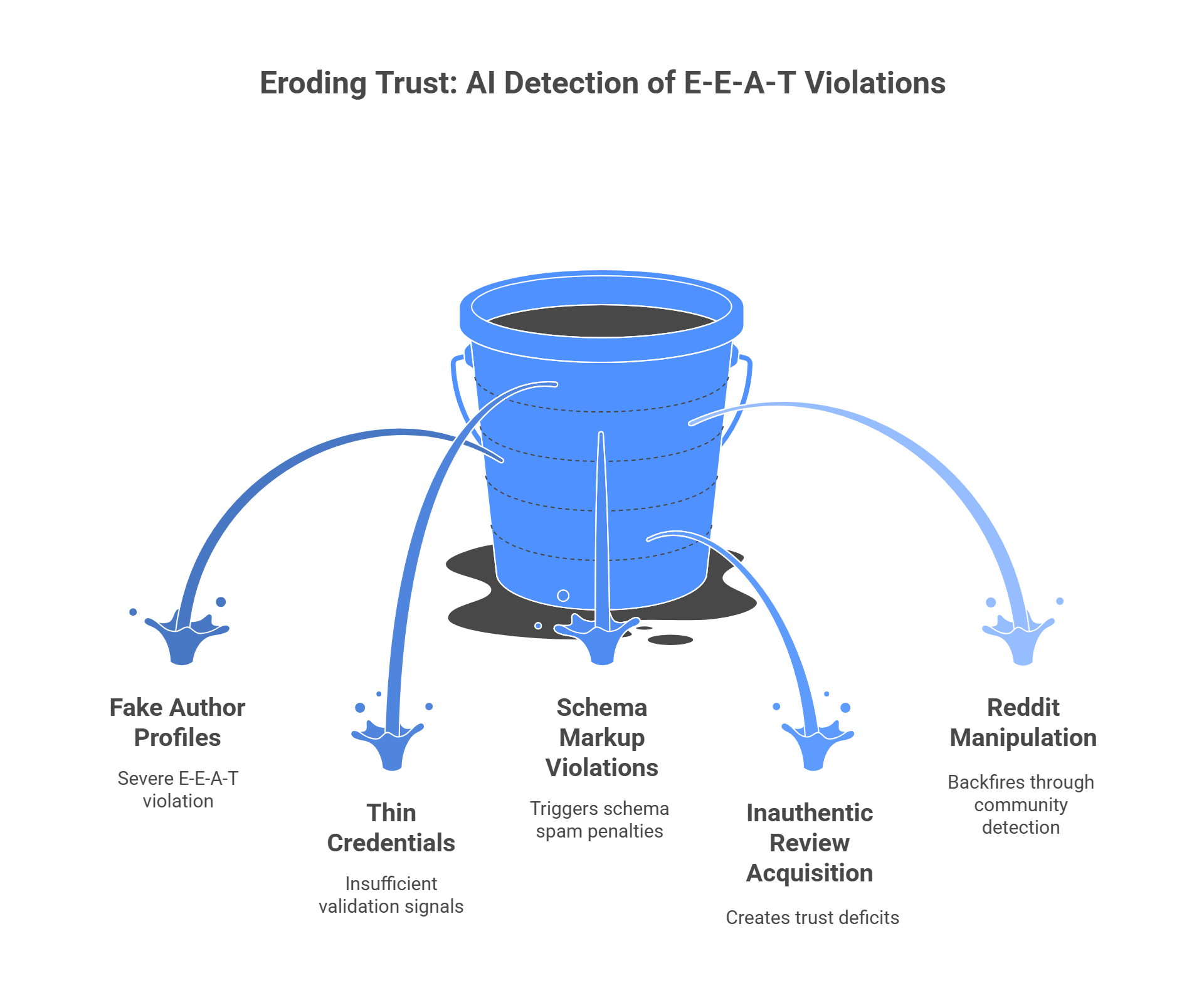
Fake or Fabricated Author Profiles:
Creating fictional expert personas with stock photos, fabricated credentials, or non-existent institutional affiliations represents the most severe E-E-A-T violation. AI systems cross-reference author claims against LinkedIn profiles, university alumni databases, professional licensing boards, and Knowledge Graph entities (detecting inconsistencies that trigger content de-prioritization). When authors lack verification pathways (LinkedIn shows no employment history, university has no alumni record, medical board shows no license), AI confidence scores plummet below citation thresholds.
Detection Methods AI Systems Use: Cross-platform credential verification (checking LinkedIn endorsements against stated expertise), reverse image search on author photos (identifying stock photography), entity resolution attempting to link author name to Knowledge Graph presence (absence signals low authority), temporal consistency checking (author claims 10 years experience but LinkedIn shows 3-year employment history).
Thin or Generic Credentials:
Author bios stating vague expertise ("marketing expert with years of experience") without specific credentials, quantifiable achievements, or verifiable institutional affiliations provide insufficient validation signals. Generic titles like "Content Specialist" or "Digital Marketing Professional" lack the specificity AI systems require to assess true domain expertise.
"What you can do is 'prove' your E-E-A-T."
— u/Intelligent-Aside-67, r/SEO Reddit Thread
Common Manifestations: Author profiles listing job titles without company names or dates, credentials mentioned without verification links (claiming "MBA" without specifying institution), social media links pointing to inactive or sparsely populated profiles (100 LinkedIn connections, no endorsements), missing Person schema implementation leaving no structured validation pathway.
⚠️ Keyword-Stuffed or Improper Schema Implementation
Schema Markup Violations:
Overloading schema with irrelevant keywords or implementing markup that doesn't match actual page content triggers schema spam penalties similar to historical keyword stuffing. Examples include FAQ schema where questions/answers don't appear in visible content, Person schema claiming expertise in 20+ unrelated fields, Organization schema listing fake awards or non-existent credentials.
Validation Failures: Google Rich Results Test showing errors or warnings, Search Console reporting "Unparsable structured data" or "Missing field" errors, schema properties containing keyword-stuffed text instead of natural language (knowsAbout: "SEO, AEO, GEO, AI SEO, search optimization, rankings" instead of legitimate expertise areas).
💸 Review Farming and Citation Manipulation
Inauthentic Review Acquisition:
Purchasing G2/Capterra reviews, incentivizing reviews with monetary compensation, or creating fake buyer accounts to post positive reviews creates trust deficits AI systems detect through verification status, review pattern analysis, and cross-platform sentiment consistency checks. When 50 five-star reviews appear within one week from accounts with no prior review history, AI confidence algorithms flag suspicious activity.
Reddit/Community Manipulation: Creating multiple accounts to upvote brand mentions, posting promotional content disguised as authentic recommendations, or coordinating vote brigading campaigns typically backfires through community detection and downvoting, moderator removal, or subreddit bans. AI systems tracking Reddit citations discount heavily downvoted threads or deleted posts.
"Top 4 can be easily manipulated/gamed tho."
— u/Ozymandia5, r/SEO Reddit Thread
🔧 E-E-A-T Recovery and Remediation Strategies
Immediate Damage Control (Weeks 1-4):
Audit and Remove Violations: Identify all fake author profiles, fabricated credentials, or keyword-stuffed schema, remove or replace inauthentic author content with genuinely credentialed experts, delete improperly implemented schema markup causing validation errors, request removal of purchased reviews or fake testimonials.
Transparent Disclosure: If previous content lacked proper attribution, add "Updated [date]: Author credentials and review process implemented" notices, publicly acknowledge improvements to editorial standards without admitting past manipulation, demonstrate commitment to authentic E-E-A-T signal development.
⏰ Foundation Rebuilding (Months 2-6)
Authentic Author Development: Hire or contract with genuinely credentialed subject matter experts matching content topic areas, create comprehensive author profiles with LinkedIn verification, educational credentials, published work portfolios, implement proper Person schema with sameAs links to verifiable social profiles.
Organic Review Acquisition: Launch systematic customer success outreach identifying satisfied users willing to provide detailed reviews, implement post-purchase email sequences (30-60 days after implementation when value realization occurs) requesting authentic feedback, respond to all reviews (positive and negative) demonstrating active engagement.
Content Quality Overhaul: Audit existing content for depth, accuracy, and unique insights, add experience narratives with specific implementation details, methodology transparency, results quantification, incorporate expert quotes from interviews with recognized industry authorities, implement FAQ schema based on actual user questions from support tickets or community forums.
💎 Authority Maturation (Months 7-18)
Third-Party Validation Building: Pursue earned media placements in tier-2 publications (industry blogs, vertical-specific media) before targeting tier-1 outlets, secure conference speaking opportunities at regional events building toward national conferences, contribute expert commentary to journalist queries (HARO, Qwoted) establishing media relationships.
Knowledge Graph Entity Claiming: Build Wikipedia notability through accumulation of independent press coverage in reliable sources, create properly sourced Wikipedia entries following neutral point of view guidelines, claim Knowledge Graph entities via Google Search Console, maintain consistent NAP+E across digital properties.
Community Engagement Normalization: Participate authentically in Reddit communities through disclosed company representative accounts, provide genuine value through detailed technical assistance, implementation guidance without promotional links, earn organic upvotes and community trust through consistent helpful participation over months.
📊 Recovery Timeline Expectations by Violation Severity
Minor Violations (thin author bios, schema validation errors): 2-4 months for citation eligibility recovery with proper implementation of comprehensive author profiles and schema fixes.
Moderate Violations (keyword-stuffed schemas, some inauthentic reviews): 6-9 months requiring complete content audit, schema reimplementation, gradual organic review accumulation.
Severe Violations (fake author profiles, systematic review farming, community manipulation): 12-18 months demanding complete author roster replacement, third-party validation rebuilding, extended community trust rehabilitation.
The critical insight is that E-E-A-T recovery cannot be accelerated through technical fixes alone (it requires time for authentic signals to accumulate and for AI systems to re-evaluate trust scoring based on consistent positive evidence). Organizations should set realistic expectations that severe E-E-A-T damage may require complete brand repositioning or domain migration in extreme cases where trust deficits prove insurmountable.
Q12. How Does E-E-A-T Strategy Differ Across AI Platforms and How Do You Optimize for Multi-Platform Citations? [toc=Multi-Platform Strategy]
The AI search landscape is fracturing into platform-specific ecosystems, each employing distinct source selection algorithms and E-E-A-T evaluation criteria. Google AI Overviews pull 70% of sources from the top 10 organic search results, requiring traditional SEO foundations plus comprehensive schema implementation. ChatGPT prioritizes Bing-indexed sources with conversational Q&A formatting and clear expertise signals. Perplexity favors recent content published within the last 30-60 days with diverse source validation and citation-ready statistics. Claude emphasizes long-form comprehensive guides exceeding 3,000 words with detailed methodology transparency and academic-style citations. These divergent requirements demand platform-specific E-E-A-T optimization strategies rather than one-size-fits-all approaches traditional agencies employ.
❌ The Traditional Agency Single-Platform Gap
Most SEO agencies optimize exclusively for Google, focusing on organic ranking factors, Google-specific schema, and Search Console data. Their deliverables center on keyword rankings, backlink acquisition for PageRank transfer, and featured snippet optimization (metrics that provide limited visibility into ChatGPT, Perplexity, Claude, or emerging AI platforms where increasingly large segments of target ICPs conduct product research, competitive analysis, and purchase decision-making). This Google-only approach leaves clients completely invisible to ChatGPT's 1 billion daily queries, Perplexity's 10 million+ monthly users seeking research-quality answers, and Claude's growing enterprise adoption for internal knowledge work.
"It's not just about ranking anymore, it's about being the answer."
— u/CricketInvasion, r/seogrowth Reddit Thread
The business impact is severe: brands achieving page-one Google rankings may miss 40-60% of potential AI-referred traffic and citations by ignoring platform-specific optimization requirements. When a VP of Marketing searches "best marketing automation platforms" in ChatGPT versus Google, they encounter entirely different result sets (with ChatGPT citing third-party comparison articles, Reddit recommendations, and YouTube tutorials while Google surfaces brand homepages and paid placements). Traditional agencies optimizing exclusively for Google systematically miss these alternative citation pathways.
🎯 Platform-Specific E-E-A-T Requirements
Google AI Overviews Citation Criteria:
Google AI Overviews require top 10 organic ranking as a prerequisite (70% of sources already rank highly), plus comprehensive schema implementation including Person, Organization, FAQ, HowTo markup enabling direct answer extraction. Featured snippet optimization remains critical (content formatted as answer-first paragraphs, question-based H2/H3 headings, bulleted key points for scannable extraction, and table-based comparisons for structured data). Domain authority thresholds matter significantly, with DA 50+ sites achieving substantially higher inclusion rates.
ChatGPT Source Selection:
ChatGPT relies on Bing indexing as its primary retrieval mechanism, requiring Bing Webmaster Tools setup with sitemap submission separate from Google Search Console. Content must use conversational Q&A format with natural language questions and direct answers rather than SEO keyword-stuffed headings. Author credibility signals including comprehensive bios, LinkedIn verification, and expert credentials receive heavier weighting than in traditional Google ranking. ChatGPT shows preference for long-form comprehensive content (2,000+ words) covering topics exhaustively rather than thin 500-word blog posts.
"LLMs favor authentic, up-to-date expertise — not cookie-cutter SEO content."
— Reddit User, r/content_marketing Reddit Thread
Perplexity's Recency and Diversity Priorities:
Perplexity demonstrates strong preference for content published within the last 30-60 days, making content freshness protocols with systematic monthly updates critical. Unlike Google or ChatGPT which may cite 1-3 sources per answer, Perplexity typically includes 5-10 diverse citations per response, requiring competitive differentiation through unique data points, original research, or proprietary insights not available in competitor content. Citation-ready statistics, data visualizations, and quantified claims receive priority over narrative-only content. Perplexity's research-style interface favors academic and journalistic sources with transparent methodologies, clear source attribution, and fact-checking protocols.
Claude's Comprehensive Deep-Dive Preference:
Claude's 200,000 token context window enables processing of extremely long documents, creating preference for comprehensive pillar content exceeding 3,000 words with exhaustive subtopic coverage. Content must demonstrate clear expertise signals through detailed methodology transparency, discussing edge cases, implementation challenges, alternative approaches, and nuanced analysis that surface-level content omits. Academic-style citation practices with hyperlinked references to primary sources strengthen citation confidence. Claude's safety-focused design prioritizes authoritative institutional sources over individual blogs, making author credentials and organizational affiliation particularly critical.
✅ MaximusLabs Multi-Platform E-E-A-T Optimization Framework
We implement simultaneous optimization across all major AI platforms through our proprietary "Search Everywhere Optimization" methodology, ensuring comprehensive citation eligibility:
Cross-Platform Technical Foundation: Google indexing and organic ranking optimization (traditional SEO maintaining top 10 positions for core queries), Bing Webmaster Tools setup with separate sitemap submission and crawl optimization (ChatGPT eligibility), canonical URL consistency preventing content fragmentation across platforms, mobile-first responsive design meeting all platforms' technical requirements.
Adaptive Content Architecture: Conversational Q&A formatting with question-based structure (ChatGPT/Claude preferences), answer-first paragraphs providing 200-320 character extractable responses (Google AI Overviews), systematic freshness protocols with monthly content updates on high-priority pages (Perplexity recency requirements), comprehensive topical coverage with 3,000+ word pillar pages (Claude depth preferences), FAQ schema implementation with 8-12 Q&A pairs per article (multi-platform answer extraction).
Unified Schema Strategy: Person, Organization, Author schemas with consistent @id entity linking across all content, FAQ schema for structured question-answer pairs (Google, ChatGPT), HowTo schema for procedural content (Google, Perplexity), Article schema with nested entity relationships (cross-platform credibility), validation across Google Rich Results Test and Schema.org validators ensuring error-free implementation.
Platform-Agnostic Authority Building: Knowledge Graph entity claiming for founders and organization (all platforms query), Wikipedia presence with proper sourcing meeting notability standards (universal authority signal), LinkedIn optimization with 5,000+ connections and comprehensive profiles (author verification), third-party validation through Reddit engagement, YouTube tutorials, G2 reviews (cited across platforms), media coverage in tier-1 publications establishing brand recognition (cross-platform trust signal).
Multi-Format Content Distribution: Long-form text content (3,000+ words for Claude, Perplexity), video tutorials and demonstrations (YouTube citations in ChatGPT, Perplexity), podcast appearances and audio content (emerging citation source), infographics and data visualizations (Perplexity research-style answers), interactive tools and calculators (unique value proposition).
📈 Multi-Platform Results and Competitive Advantage
A B2B SaaS client achieved 23% of demo requests from AI-referred traffic within 9 months of implementing our multi-platform E-E-A-T framework (distributed across Google AI Overviews (40% of AI traffic with highest intent signals and immediate purchase readiness), ChatGPT (35% of AI traffic representing research-phase users conducting vendor discovery), Perplexity (20% of AI traffic from comparison shoppers evaluating multiple solutions), and Claude (5% of AI traffic primarily technical evaluators assessing implementation complexity)).
This diversified citation portfolio achieved 6x higher conversion rate from AI-referred visitors compared to traditional organic search, with average deal sizes 40% larger due to the extensive pre-qualification and education users received through comprehensive AI-generated answers before reaching the website. The strategic advantage is clear: multi-platform E-E-A-T optimization delivers higher-value traffic at scale by ensuring citation eligibility across all platforms where target audiences conduct research, compared to single-platform traditional SEO approaches that miss the majority of AI search opportunity and systematically under-deliver on pipeline contribution.
MaximusLabs' Search Everywhere Optimization eliminates the complexity of managing platform-specific requirements by implementing unified E-E-A-T architecture that satisfies all major AI platforms simultaneously (ensuring comprehensive market coverage, maximum citation frequency, and superior ROI compared to fragmented single-platform strategies traditional agencies continue deploying).
.png)

.png)
