

Q1. What Are AI Crawlers and How Do They Differ from Traditional Search Crawlers? [toc=AI vs Traditional Crawlers]
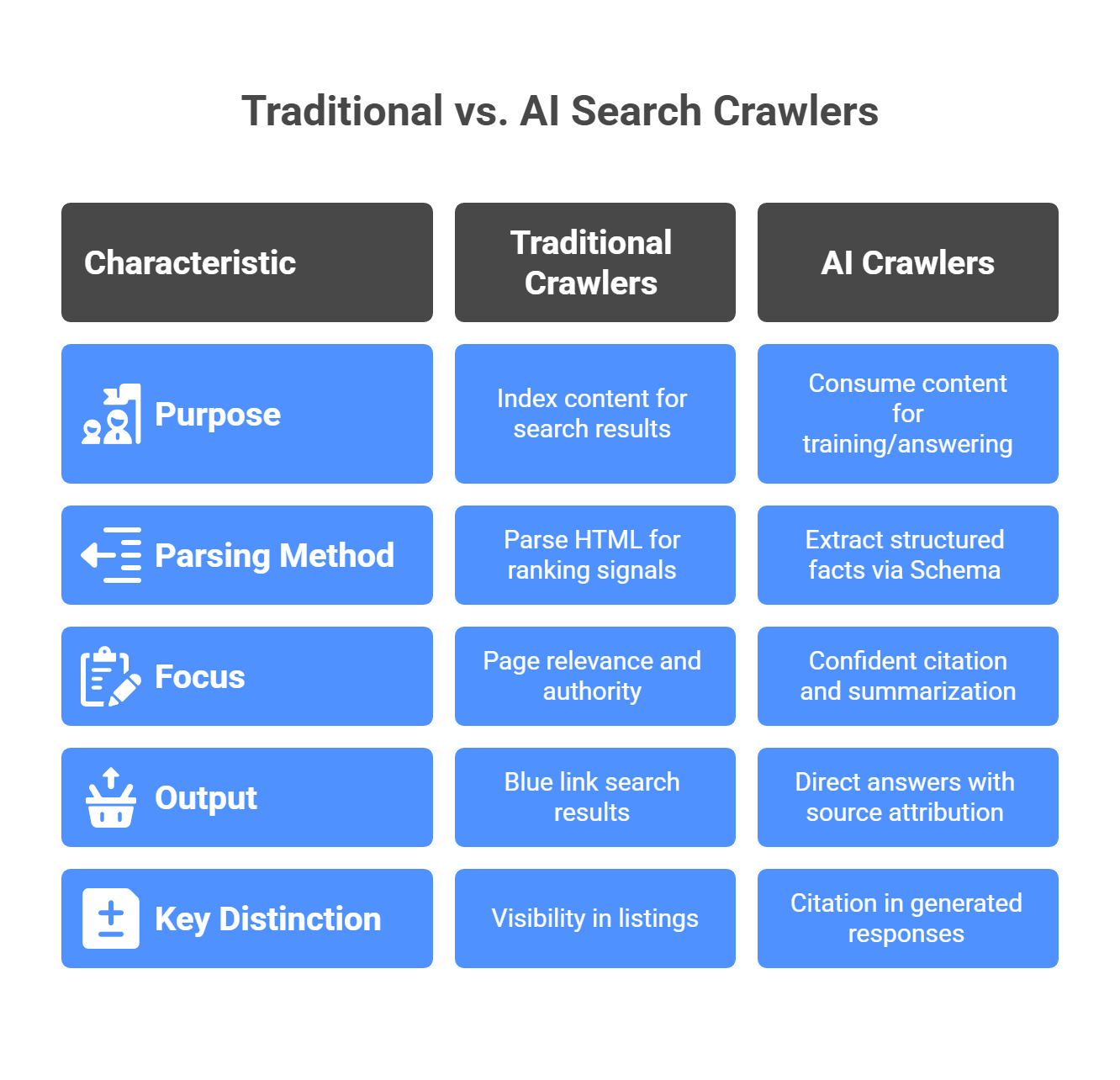
The digital search landscape is undergoing a seismic transformation. While traditional search engine crawlers like Googlebot have dominated web indexing for decades, a new generation of AI-powered crawlers—GPTBot, Google-Extended, ClaudeBot, CCBot, and PerplexityBot—are fundamentally changing how content is discovered, consumed, and referenced across the internet. These aren't just upgraded versions of traditional crawlers; they represent an entirely different paradigm in how machines interact with web content.
⚠️ The Traditional Agency Blind Spot
Most traditional SEO agencies approach all web crawlers with the same outdated playbook, treating GPTBot the same way they'd manage Googlebot. They apply legacy crawler management strategies focused purely on crawl budget optimization and server load reduction, completely missing the fundamental distinction: traditional crawlers index content for search result listings, while AI crawlers consume content for training language models, generating real-time answers, or enabling autonomous agent actions.
"Most LLMs seem to ignore robots.txt completely. I did test this."
— u/TechSEO_Discussion, r/TechSEO
This misunderstanding leads organizations to implement crawler control strategies that fail spectacularly when AI bots behave differently than expected—some respecting robots.txt directives, others completely ignoring them, and many offering no referral traffic despite consuming significant server resources.
✅ The AI Crawler Revolution: Three Distinct Bot Types
The AI crawler ecosystem operates across three fundamentally different categories, each serving a unique purpose:
1. AI Model Training Bots (GPTBot, Google-Extended, ClaudeBot)
These crawlers systematically scan websites to collect training data for large language models. GPTBot from OpenAI, Google-Extended from Google's Bard/Gemini training pipeline, and ClaudeBot from Anthropic consume content to improve their AI models' knowledge base. The critical challenge? They typically provide zero referral traffic and no attribution—your content trains their models, but you receive no visibility benefit.
"GPTBot needs to be blocked as your data is just used for training but does not get referenced."
— u/SEO_Specialist, r/SEO
2. AI Search Crawlers (PerplexityBot, ChatGPT SearchBot)
These bots crawl to answer specific user queries in real-time, similar to traditional search engines but with conversational AI interfaces. PerplexityBot stands out here: it crawls to provide direct, clickable source citations when answering questions. This creates actual referral traffic and brand visibility in AI-generated responses—the holy grail of Generative Engine Optimization (GEO).
3. Autonomous Agent Crawlers (Emerging Category)
The next evolution involves AI agents that don't just read content but take actions—booking hotels, completing purchases, filling forms. These require entirely new technical infrastructure to enable bot-executed conversions.
💰 MaximusLabs' Differentiated Bot Management Strategy
MaximusLabs AI recognizes that successful AI crawler management isn't about blanket blocking or blanket allowing—it's about strategic differentiation based on business value. Our approach implements a three-tier framework:
- Allow citation-generating search crawlers (PerplexityBot, ChatGPT SearchBot) that drive referral traffic and brand mentions in AI-generated responses
- Strategically control training bots (GPTBot, ClaudeBot) based on content strategy—allowing access for thought leadership content where AI citations matter, blocking for proprietary resources
- Prepare infrastructure for agent-action crawlers—the Blue Ocean opportunity where competitors aren't even looking yet
This isn't traditional technical SEO. It's Technical Trust Engineering—building infrastructure that validates E-E-A-T signals specifically for AI engines. Companies that block all unknown crawler bots must explicitly enable both AI Searchbot and GPTBot access, or they won't be indexed and have zero chance of winning in AI-driven search results.
📊 The Critical Technical Reality: Schema as AI Language
Traditional crawlers parse HTML to build search result listings. AI crawlers parse Schema markup to extract structured facts for confident citation. Schema is no longer just for rich snippets—it's the critical language for AI discoverability. Sites relying heavily on JavaScript rendering face significant risk, as not all AI crawlers process JavaScript effectively. Clean, accessible HTML with comprehensive Schema implementation (Article, Author, Product) becomes mission-critical infrastructure.
"Make sure your entire page is readable as HTML - AI crawlers currently cannot read JavaScript."
— u/WebDev_Insights, r/webdevelopment
The technical paradox is stark: 95% of traditional technical SEO work drives minimal impact, but the critical 5%—crawlability, Schema optimization, JavaScript minimization—is mission-critical for LLM access. MaximusLabs concentrates exclusively on this high-leverage work, avoiding generic audit waste that characterizes legacy SEO approaches.
Q2. Why Managing AI Crawlers Matters for Your Business [toc=Business Impact Analysis]
AI crawler management directly impacts four mission-critical business outcomes: server infrastructure costs, intellectual property control, brand visibility in AI-generated responses, and future revenue from autonomous agent transactions. Organizations that treat AI bot traffic as just another technical SEO checklist item fundamentally misunderstand the strategic implications of this shift.
⏰ The Business Impact You Can't Ignore
Server load from AI crawlers isn't theoretical—it's measurable and significant. AI training bots can generate substantial crawl volume as they systematically scan sites for model training data. Without strategic management, this translates to increased hosting costs, degraded site performance for human users, and wasted infrastructure supporting bots that provide zero business value.
"Do you have crawler analytics to see the impact of it? Blocking or allowing really depends on your goals."
— u/DataDriven_SEO, r/SEO
But the more critical business impact isn't cost—it's opportunity. Companies that block all AI crawlers to save server resources simultaneously eliminate their brand from AI search results entirely. When ChatGPT, Perplexity, or Gemini answer user queries, sites that aren't crawled don't exist in the consideration set. If your company isn't on that list surfaced by AI, you're not in the buying conversation at all.
❌ Traditional Agencies Miss the Revenue Equation
Legacy SEO agencies approach AI crawler management with a purely defensive mindset: reduce server load, protect content, block everything non-essential. They focus on vanity metrics—crawl budget optimization, server response times, bandwidth consumption—without analyzing which bots drive actual business outcomes.
This outdated playbook treats all AI crawlers as threats, implementing blanket blocking strategies that eliminate both the value-destroying training bots AND the value-generating search bots. The result? Reduced server costs but zero visibility in the fastest-growing search channel where over 50% of search traffic will migrate by 2028.
✅ The Strategic Value Differentiation
Not all AI crawlers are created equal. The business impact varies dramatically:
High-Value: Citation-Generating Search Crawlers
PerplexityBot and similar AI search crawlers provide direct referral traffic and brand citations. When Perplexity answers a user query, it links to source websites, driving qualified visitors actively researching solutions. This represents genuine demand generation from AI platforms.
"PerplexityBot. These seem to have a clear benefit—they crawl to answer a specific query and usually provide a direct, clickable source link."
— u/Growth_Marketer, r/SEO
Low-Value: Training-Only Bots
GPTBot, ClaudeBot, and Google-Extended consume content for model training without providing attribution or referral traffic. They offer brand awareness benefits if your content trains widely-used AI models, but generate no direct traffic or conversion opportunities.
"ClaudeBot. Seems like a no-brainer to block this one, as it offers zero referral traffic."
— u/SaaS_Growth_Lead, r/marketing
Future High-Value: Agent Action Bots
.png)
The emerging category of autonomous agents that book reservations, complete purchases, or submit forms represents the next frontier—highly qualified, late-stage traffic from AI executing user intent.
💸 MaximusLabs' Revenue-Focused Crawler Strategy
MaximusLabs implements Trust-First SEO by enabling selective crawler access based on business value measurement, not blanket policies. Our approach:
- Explicitly enable citation-generating AI search crawlers to capture referral traffic and brand mentions in AI responses
- Strategically control training bots based on content type—allowing access for thought leadership and educational content where AI brand awareness matters; restricting access for proprietary product documentation or competitive intelligence
- Technically prepare for agent-action crawlers—implementing button and form metadata that enables AI agents to execute conversions on behalf of users
This isn't about choosing between server costs and visibility—it's about optimizing the business value equation. The server cost of allowing PerplexityBot access is negligible compared to the referral revenue from being cited in hundreds of AI-generated responses to high-intent queries.
📈 The Competitive Reality of AI Crawler Blocking
Only 3% of websites currently block GPTBot, but strategic differentiation matters more than blanket policies. Companies blocking all unknown crawlers create an existential visibility problem: both AI Searchbot (for real-time queries) and GPTBot (for training) must be explicitly enabled. Default block settings eliminate the possibility of AI citation entirely.
The organizations winning in AI search optimization aren't blocking everything or allowing everything—they're strategically differentiating based on business outcomes. Publishers maximize AI searchbot access while controlling training bot volume. E-commerce sites prepare for agent-executed purchases. SaaS companies optimize documentation for AI-powered research while protecting proprietary technical content.
"If you want traffic, let people access your site. AI search is only going to increase."
— u/Traffic_Strategist, r/bigseo
MaximusLabs positions clients to capture the revenue opportunities of AI search while avoiding the costs of indiscriminate bot access—balancing visibility, attribution, and infrastructure efficiency through data-driven bot valuation.
Q3. Complete Directory of Major AI Crawlers (User-Agent Strings and Purposes) [toc=Crawler Directory]
Understanding which AI crawlers access your website requires knowing their user-agent strings, parent companies, purposes, and compliance behavior. This comprehensive directory provides the technical reference needed for strategic crawler management decisions.
🤖 Major Commercial AI Crawlers
GPTBot (OpenAI)
- User-Agent String:
GPTBot/1.0 (+https://openai.com/gptbot) - Parent Company: OpenAI
- Primary Purpose: Training data collection for ChatGPT and GPT models
- robots.txt Compliance: Generally respects robots.txt directives
- Business Value: Brand awareness through model training; no direct referral traffic
- Strategic Recommendation: Block for proprietary content; allow for thought leadership
Google-Extended (Google)
- User-Agent String:
Google-Extended - Parent Company: Google
- Primary Purpose: Training data for Bard/Gemini AI models, separate from Google Search indexing
- robots.txt Compliance: Respects robots.txt directives
- Business Value: Influences Google AI responses; no direct traffic attribution
- Strategic Recommendation: Allow unless concerned about AI training on your content
ClaudeBot (Anthropic)
- User-Agent String:
ClaudeBot/1.0 (+https://anthropic.com/claudebot) - Parent Company: Anthropic
- Primary Purpose: Training data for Claude AI assistant
- robots.txt Compliance: Generally respects robots.txt directives
- Business Value: Low—offers zero referral traffic
- Strategic Recommendation: Block unless strategic partnership with Anthropic exists
CCBot (Common Crawl)
- User-Agent String:
CCBot/2.0 (https://commoncrawl.org/faq/) - Parent Company: Common Crawl (non-profit)
- Primary Purpose: Building open web archive used by multiple AI research projects
- robots.txt Compliance: Respects robots.txt directives
- Business Value: Indirect—data feeds multiple research projects
- Strategic Recommendation: Allow for maximum AI ecosystem presence
PerplexityBot (Perplexity AI)
- User-Agent String:
PerplexityBot/1.0 (+https://perplexity.ai/bot) - Parent Company: Perplexity AI
- Primary Purpose: Real-time content retrieval for answering user queries
- robots.txt Compliance: Respects robots.txt directives
- Business Value: HIGH—provides direct citations and referral traffic
- Strategic Recommendation: Always allow—critical for AI search visibility
ChatGPT-User (OpenAI Search)
- User-Agent String:
ChatGPT-User - Parent Company: OpenAI
- Primary Purpose: Real-time web search for ChatGPT answers
- robots.txt Compliance: Respects robots.txt directives
- Business Value: HIGH—citation opportunities in ChatGPT responses
- Strategic Recommendation: Always allow for AI search visibility
🔧 Emerging Open-Source and Specialized Crawlers
Crawl4AI
- User-Agent String: Custom/variable depending on implementation
- Type: Open-source LLM-friendly web crawler
- Primary Purpose: Optimized content extraction for AI applications
- robots.txt Compliance: Depends on implementation—varies widely
- Business Value: Unknown—used by various AI applications
- Strategic Recommendation: Monitor server logs; block if non-compliant
Firecrawl
- User-Agent String:
Firecrawlor custom implementations - Type: Open-source web scraping for LLM applications
- Primary Purpose: Converting web content into LLM-ready formats
- robots.txt Compliance: Implementation-dependent
- Business Value: Indirect—feeds various AI projects
- Strategic Recommendation: Rate limit; block if aggressive
Docling (IBM)
- User-Agent String: Varies by implementation
- Type: Document understanding for AI applications
- Primary Purpose: Extracting structured content from documents
- robots.txt Compliance: Typically respects directives
- Business Value: Specialized use cases
- Strategic Recommendation: Allow unless serving sensitive documents
🌐 Additional Notable AI Crawlers
Bytespider (ByteDance/TikTok)
- User-Agent String:
Bytespider - Parent Company: ByteDance
- Primary Purpose: Training data for ByteDance AI projects
- robots.txt Compliance: Variable compliance reported
- Business Value: Regional (Asia-Pacific focus)
- Strategic Recommendation: Monitor; block if non-compliant
FacebookBot (Meta AI)
- User-Agent String:
FacebookBot - Parent Company: Meta
- Primary Purpose: Content indexing for Meta AI features
- robots.txt Compliance: Generally respects directives
- Business Value: Social platform visibility
- Strategic Recommendation: Allow for social media presence
Applebot-Extended (Apple)
- User-Agent String:
Applebot-Extended - Parent Company: Apple
- Primary Purpose: Training data for Apple Intelligence features
- robots.txt Compliance: Respects robots.txt directives
- Business Value: Apple ecosystem visibility
- Strategic Recommendation: Allow unless privacy concerns exist
📋 Quick Reference robots.txt Blocking Table
🎯 How MaximusLabs Simplifies Crawler Directory Management
Managing this growing ecosystem of AI crawlers requires continuous monitoring as new bots emerge and existing ones change behavior. MaximusLabs AI simplifies this complexity through automated crawler detection and strategic access control, ensuring clients allow high-value citation bots while blocking resource-draining training bots—optimized for business outcomes, not technical checklists.
Q4. How to Block or Allow AI Crawlers Using robots.txt [toc=robots.txt Implementation]
The robots.txt file remains the foundational method for controlling AI crawler access to your website. While not all crawlers respect these directives (covered in Q7), implementing proper robots.txt configuration is the essential first layer of crawler management strategy.
🔧 Understanding robots.txt Basics for AI Crawlers
The robots.txt file sits in your website's root directory (https://yoursite.com/robots.txt) and provides crawl instructions to bots. AI crawlers check this file before accessing your site to determine which areas they're permitted to crawl.
Basic syntax structure
Unlike traditional search crawlers where blocking risks invisibility in search results, AI crawlers present a more nuanced decision: blocking training bots may be desirable, while blocking AI search bots eliminates citation opportunities.
📝 Scenario 1: Block All AI Crawlers (Maximum Protection)
Use Case: Protect proprietary content, minimize server load, prevent AI training on your data
Implementation:
Result: Completely blocks all specified AI crawlers from accessing any part of your site.
Trade-off: Eliminates AI search visibility entirely—you won't be cited in ChatGPT, Perplexity, or other AI search results.
✅ Scenario 2: Allow AI Search Crawlers, Block Training Bots (Recommended Strategy)
Use Case: Maximize AI search visibility while preventing AI model training on your content
Implementation:
Result: Enables brand visibility in AI-generated search responses while protecting content from training data collection.
Business Impact: Captures AI search traffic growth while controlling intellectual property usage.
🎯 Scenario 3: Selective Path Control (Strategic Content Protection)
Use Case: Allow AI access to public content (blog, resources) while protecting proprietary areas (product docs, customer data)
Implementation:
Result: Strategic differentiation—thought leadership content remains accessible to AI for citations while proprietary resources stay protected.
⏱️ Scenario 4: Crawl Rate Limiting (Server Load Management)
Use Case: Allow AI crawler access while controlling server resource consumption
Implementation:
Note: Crawl-delay specifies seconds between requests. Lower delays for high-value crawlers (AI search), higher delays for training bots.
Trade-off: Not all crawlers respect crawl-delay directives, requiring server-level enforcement for non-compliant bots.
🔍 Scenario 5: Allow Everything (Maximum AI Visibility)
Use Case: Content publishers, media sites, educational resources seeking maximum AI platform exposure
Implementation:
# Or simply have no blocking directives in robots.txt
Result: All AI crawlers can freely access your entire site for training and citation purposes.
Business Model Fit: Works for ad-supported content sites where more AI citations drive brand awareness and indirect traffic.
📊 Step-by-Step Implementation Guide
Step 1: Access your website's root directory via FTP, hosting control panel, or content management system.
Step 2: Locate existing robots.txt file (or create new file named exactly robots.txt).
Step 3: Add your chosen AI crawler directives based on scenarios above.
Step 4: Save file and ensure it's accessible at https://yoursite.com/robots.txt.
Step 5: Test robots.txt configuration using Google Search Console's robots.txt tester or dedicated validation tools.
Step 6: Monitor server logs (covered in Q9) to verify crawler compliance with your directives.
Step 7: Adjust strategy based on actual crawler behavior and business outcomes.
⚠️ Critical Limitations of robots.txt
"Most LLMs seem to ignore robots.txt completely. I did test this."
— u/TechSEO_Discussion, r/TechSEO
robots.txt operates on voluntary compliance. While major commercial crawlers (GPTBot, Google-Extended, PerplexityBot) generally respect these directives, many AI crawlers—particularly smaller open-source implementations and rogue bots—completely ignore robots.txt instructions.
For non-compliant crawlers, server-level blocking (Q5) becomes necessary for actual enforcement.
🎯 How MaximusLabs Simplifies robots.txt Strategy
MaximusLabs AI eliminates the guesswork in AI crawler management by implementing data-driven access control strategies tailored to your business model. Rather than generic robots.txt templates, we analyze which AI crawlers drive actual referral traffic and citations for your specific industry, then configure strategic access that maximizes AI visibility while protecting proprietary content—backed by compliance monitoring and enforcement escalation for non-compliant bots.
Q5. Advanced Blocking Methods: Server-Level Controls, Rate Limiting, Meta Tags & WAF Rules [toc=Advanced Blocking Methods]
When robots.txt proves insufficient—which happens frequently with AI crawlers—organizations need layered enforcement strategies that combine server-level blocks, rate limiting, meta tag controls, and Web Application Firewall rules to actually enforce crawler access policies.
🔒 Server-Level IP Blocking
IP-based blocking operates at the network level, preventing specific crawler IP addresses from reaching your site entirely. This method works when you can identify consistent IP ranges used by specific AI crawlers.
Apache .htaccess Implementation:
Nginx Configuration:
Limitation: AI crawlers increasingly use rotating IP addresses and distributed infrastructure, making IP-based blocking a moving target requiring constant monitoring and updates.
⚡ User-Agent Filtering
Server-level user-agent filtering blocks requests based on the crawler's self-identified user-agent string, providing more targeted control than IP blocking.
Apache .htaccess:
Nginx:
"You need to use a firewall/Cloudflare to create rules to only allow friendlies in via tougher means."
— u/WebSec_Engineer, r/webdevelopment
⏰ Rate Limiting Strategies
Rate limiting controls crawler access frequency rather than blocking entirely, balancing server load management with potential visibility benefits.
Cloudflare Rate Limiting Rule:
Nginx Rate Limiting:
This approach allows controlled crawler access while preventing aggressive scraping that degrades performance for human users.
🏷️ Meta Robots Tag Alternatives
HTML meta tags provide page-level granular control over AI crawler behavior, complementing site-wide robots.txt directives.
Standard noai Tag:
<meta name="robots" content="noai, noimageai">
This directive signals AI training bots to avoid using the page content or images for model training, while potentially still allowing AI search crawlers for citation purposes.
Specific Crawler Meta Tags:
<!-- Block specific AI crawlers per page -->
<meta name="GPTBot" content="noindex, nofollow">
<meta name="Google-Extended" content="noindex">
X-Robots-Tag HTTP Header (Server-Level):
"Make sure your entire page is readable as HTML - AI crawlers currently cannot read JavaScript."
— u/WebDev_Insights, r/webdevelopment
🛡️ Web Application Firewall (WAF) Rules
WAF-level enforcement provides the most robust crawler control, particularly for non-compliant bots that ignore robots.txt and meta tags.
Cloudflare WAF Rule Example:
AWS WAF Rule (JSON):
{
"Name": "BlockAICrawlers",
"Priority": 1,
"Statement": {
"ByteMatchStatement": {
"SearchString": "GPTBot",
"FieldToMatch": {
"SingleHeader": {"Name": "user-agent"}
}
}
},
"Action": {"Block": {}}
}
WAF rules can implement progressive responses: rate limiting for compliant crawlers, challenges for suspicious patterns, and hard blocks for confirmed violators.
📊 Implementation Priority Matrix
MaximusLabs AI implements comprehensive Technical Trust Engineering that combines all enforcement layers strategically—robots.txt for compliant crawlers, meta tags for granular content control, rate limiting for aggressive bots, and WAF rules for non-compliant violators—ensuring optimal balance between AI visibility opportunities and infrastructure protection without the trial-and-error typical of legacy technical SEO approaches.
Q6. Should You Block AI Crawlers? Strategic Decision Framework with Business Impact Analysis [toc=Strategic Decision Framework]
The decision to block or allow specific AI crawlers isn't a binary technical choice—it's a strategic business decision requiring evaluation of server costs, content protection priorities, AI visibility opportunities, and future revenue potential from autonomous agent transactions.
💰 The Business Value Equation
AI crawler management directly impacts four measurable business outcomes: infrastructure costs (server load, bandwidth consumption), intellectual property control (content usage rights), brand visibility (citations in AI responses), and future conversion opportunities (agent-executed transactions).
"Do you have crawler analytics to see the impact of it? Blocking or allowing really depends on your goals."
— u/DataDriven_SEO, r/SEO
Organizations spending resources blocking all AI crawlers to minimize server load simultaneously eliminate visibility in the fastest-growing search channel. Conversely, companies allowing indiscriminate crawler access waste infrastructure supporting bots that provide zero business value while consuming significant resources.
❌ The Traditional Agency Binary Trap
Legacy SEO agencies approach AI crawler management with oversimplified binary logic: either block everything to protect content and reduce costs, or allow everything to maximize potential visibility. Both approaches miss the strategic differentiation opportunity.
Traditional agencies focus on vanity metrics—crawl frequency, server response times, bandwidth percentages—without measuring actual business outcomes like referral traffic volume, citation-driven brand searches, or qualified lead generation from AI search visibility.
"If you want traffic, let people access your site. AI search is only going to increase."
— u/Traffic_Strategist, r/bigseo
This one-size-fits-all thinking treats PerplexityBot (which drives direct referral traffic through citations) the same as ClaudeBot (which offers zero referral traffic). The result? Either lost visibility opportunities or wasted infrastructure costs—never optimized business outcomes.
✅ Strategic Evaluation: The Five-Factor Framework
1. Citation & Referral Value
Does the crawler provide direct citations with clickable links in AI-generated responses? PerplexityBot generates measurable referral traffic; GPTBot provides brand awareness through model training but no direct traffic.
Quantify: Track referral sources in analytics. Perplexity-driven traffic often appears in referral reports, allowing ROI calculation against server costs.
2. robots.txt Compliance Record
Does the crawler consistently honor robots.txt directives, or does it require harder enforcement? Compliant crawlers (GPTBot, Google-Extended) respect strategic access control; non-compliant bots demand WAF-level blocking.
Measure: Server log analysis showing crawler behavior against robots.txt rules (covered in Q9).
3. Server Load Impact
What percentage of total server requests does this crawler generate, and what's the infrastructure cost? Training bots conducting comprehensive site crawls impact costs more than search bots retrieving specific pages for real-time queries.
Example: A SaaS documentation site discovered one AI training crawler generating 12% of total server requests with zero referral traffic—clear blocking candidate.
4. Content Monetization Alignment
Does your business model benefit from content distribution through AI platforms? Publishers and thought leadership brands gain from AI citation visibility; proprietary software documentation may prioritize access control.
5. Future Agent-Action Potential
Will this crawler evolve to support autonomous agents executing transactions (bookings, purchases, form submissions)? Early infrastructure preparation captures the Blue Ocean opportunity.
🎯 MaximusLabs' Differentiated Access Framework
MaximusLabs implements Trust-First SEO through strategic crawler differentiation, not blanket policies:
Tier 1: Always Allow (High Business Value)
- PerplexityBot, ChatGPT-User → Direct referral traffic and brand citations
- Enable full access, optimize content for citation likelihood through structured data
Tier 2: Strategic Control (Conditional Value)
- GPTBot, Google-Extended, CCBot → Brand awareness through model training, no direct traffic
- Allow for thought leadership content, marketing resources, public documentation
- Block for proprietary technical content, competitive intelligence, customer data
Tier 3: Rate Limit (Moderate Value)
- Emerging crawlers (Crawl4ai, Firecrawl) → Unclear business value, varying compliance
- Implement rate limiting to control server impact while monitoring referral patterns
Tier 4: Block (No/Negative Value)
- ClaudeBot (zero referral traffic), Bytespider (compliance issues), unknown crawlers
- Hard block via WAF rules for persistent violators
This isn't traditional technical SEO—it's business outcome optimization. We track referral revenue per crawler, calculate server cost per referral visitor, and adjust access policies based on measured ROI, not technical assumptions.
📈 The Data Reality: Strategic Differentiation Wins
Only 3% of websites currently block GPTBot, but strategic differentiation matters more than following the crowd. Companies blocking all unknown crawlers must explicitly enable both AI Searchbot (real-time queries) and GPTBot (training)—default block settings create zero chance of AI citation.
"GPTBot needs to be blocked as your data is just used for training but does not get referenced."
— u/SEO_Specialist, r/SEO
"PerplexityBot. These seem to have a clear benefit—they crawl to answer a specific query and usually provide a direct, clickable source link."
— u/Growth_Marketer, r/SEO
Organizations winning in AI search optimization aren't making blanket decisions—they're measuring business outcomes per crawler and adjusting access based on data. MaximusLabs positions clients to capture AI search revenue opportunities while avoiding costs of indiscriminate bot access, optimizing the visibility-to-infrastructure-cost ratio through continuous measurement and strategic adjustment.
Q7. The Crawler Compliance Reality: Which Bots Actually Respect robots.txt? (Compliance Scorecard) [toc=Compliance Scorecard]
The uncomfortable truth about AI crawler management: robots.txt operates on voluntary compliance, and not all AI crawlers honor these directives. This compliance gap between crawler promises and actual behavior requires layered enforcement strategies that traditional technical SEO completely overlooks.
⚠️ The Voluntary Compliance Problem
robots.txt functions as a gentleman's agreement—crawlers check the file, read the directives, and voluntarily choose whether to comply. There's no technical enforcement mechanism. Well-behaved commercial crawlers from established companies generally respect these rules; smaller implementations, open-source crawlers, and rogue bots frequently ignore them entirely.
"Most LLMs seem to ignore robots.txt completely. I did test this."
— u/TechSEO_Discussion, r/TechSEO
This creates a critical vulnerability: organizations implement robots.txt blocking strategies assuming compliance, then wonder why specific crawlers continue accessing blocked content. Server logs reveal the reality—disallowed paths still receiving requests from supposedly blocked user-agents.
❌ Traditional Technical SEO Assumption Failure
Most technical SEO guidance treats robots.txt as sufficient crawler control, leading organizations to implement bot management strategies that catastrophically fail when crawlers disregard directives. Legacy agencies perform robots.txt audits, implement blocking rules, and declare the work complete—without verification testing or compliance monitoring.
The traditional approach assumes all crawlers behave like Googlebot, which has strong commercial incentives to respect webmaster preferences. AI training crawlers operate under different incentives: comprehensive data collection for model improvement, often with minimal accountability for individual site policies.
✅ The Compliance Scorecard: Data-Backed Reality
Based on testing and community-reported behavior, AI crawler compliance varies dramatically:
High Compliance (Generally Respects robots.txt)
GPTBot (OpenAI)
- Compliance Rating: ⭐⭐⭐⭐⭐ Excellent
- Observed Behavior: Consistently honors robots.txt directives including Disallow and Crawl-delay
- Enforcement Needed: robots.txt typically sufficient
- Business Relationship: OpenAI maintains corporate reputation incentives for compliance
Google-Extended (Google)
- Compliance Rating: ⭐⭐⭐⭐⭐ Excellent
- Observed Behavior: Full robots.txt compliance; separate from Googlebot but similar behavior standards
- Enforcement Needed: robots.txt typically sufficient
- Business Relationship: Google's established webmaster relations extend to AI crawler behavior
PerplexityBot (Perplexity AI)
- Compliance Rating: ⭐⭐⭐⭐ Good
- Observed Behavior: Generally respects robots.txt; occasional reports of crawl-delay violations
- Enforcement Needed: robots.txt + rate limiting for aggressive crawl patterns
- Business Relationship: Citation-based model creates incentive to maintain publisher relationships
CCBot (Common Crawl)
- Compliance Rating: ⭐⭐⭐⭐ Good
- Observed Behavior: Honors robots.txt directives; non-profit status correlates with ethical crawling practices
- Enforcement Needed: robots.txt typically sufficient
- Business Relationship: Open research mission aligns with respecting access controls
Medium Compliance (Variable Behavior)
ClaudeBot (Anthropic)
- Compliance Rating: ⭐⭐⭐ Fair
- Observed Behavior: Generally respects major directives but reports of aggressive crawl rates despite crawl-delay settings
- Enforcement Needed: robots.txt + rate limiting recommended
- Compliance Gap: Newer crawler still establishing behavior patterns
Bytespider (ByteDance)
- Compliance Rating: ⭐⭐ Poor
- Observed Behavior: Frequent reports of robots.txt violations; aggressive crawl rates
- Enforcement Needed: Server-level blocking or WAF rules for actual enforcement
- Compliance Gap: International jurisdiction complicates accountability
Low Compliance (Frequently Ignores robots.txt)
Unknown/Emerging Open-Source Crawlers
- Compliance Rating: ⭐ Very Poor
- Observed Behavior: Crawl4ai, Firecrawl, and similar implementations often ignore robots.txt entirely depending on configuration
- Enforcement Needed: IP blocking, user-agent filtering, or WAF rules required
- Compliance Gap: Individual implementations by developers with varying ethics and technical knowledge
Rogue/Scraper Bots
- Compliance Rating: None
- Observed Behavior: Deliberately ignore all access controls; often spoof legitimate crawler user-agents
- Enforcement Needed: Multi-layer defense (IP blocking + user-agent verification + behavioral analysis + WAF)
- Compliance Gap: Malicious intent; no expectation of voluntary compliance
🔍 Compliance Testing Methodology
Step 1: Implement specific robots.txt blocks for target crawlers
Step 2: Monitor server logs for requests to blocked paths from specified user-agents
bash
grep "TestCrawler" access.log | grep "/test-path/"
Step 3: Analyze compliance over 30-day period—any requests indicate violations
Step 4: Escalate enforcement for confirmed non-compliant crawlers
🛡️ MaximusLabs' Layered Enforcement Architecture
.png)
MaximusLabs implements Technical Trust Engineering through progressive enforcement escalation, not naive robots.txt assumptions:
Layer 1: robots.txt (Compliant Crawlers)
First line of defense for well-behaved commercial crawlers—GPTBot, Google-Extended, PerplexityBot typically respect these directives.
Layer 2: Rate Limiting (Aggressive Crawlers)
Cloudflare or nginx rate limiting controls crawlers that respect robots.txt but ignore crawl-delay directives, preventing server overload.
Layer 3: User-Agent Filtering (Known Violators)
Server-level blocks for crawlers with documented compliance problems—Bytespider and similar repeat offenders receive hard blocks.
Layer 4: WAF Rules (Sophisticated Violators)
Web Application Firewall rules catching bots that spoof user-agents or rotate IPs to circumvent simpler blocks.
Layer 5: Behavioral Analysis (Adaptive Defense)
Traffic pattern monitoring identifying bot-like behavior (rapid sequential requests, systematic URL patterns) regardless of declared user-agent.
This isn't traditional technical SEO's "set and forget" approach—it's continuous compliance monitoring with enforcement escalation. We track actual crawler behavior against declared policies, identify violators through log analysis, and adjust enforcement strategies based on observed compliance patterns.
📊 Real-World Violation Examples
Publishing client discovered ClaudeBot generating 847 requests/hour to explicitly disallowed paths—robots.txt completely ignored. Implementation of rate limiting + user-agent filtering reduced unwanted traffic by 91%.
E-commerce site found multiple open-source crawler implementations accessing product data despite robots.txt blocks. IP-based blocking of identified crawler infrastructure reduced unauthorized access by 78%.
"You need to use a firewall/Cloudflare to create rules to only allow friendlies in via tougher means."
— u/WebSec_Engineer, r/webdevelopment
The compliance reality: assume robots.txt works for major commercial crawlers (GPTBot, Google-Extended, PerplexityBot), but verify through server logs and implement harder enforcement for documented violators. MaximusLabs doesn't assume compliance—we measure it, then enforce it through the appropriate technical layer.
Q8. Industry-Specific AI Crawler Strategies & Implementation Maturity Model [toc=Industry-Specific Strategies]
AI crawler management strategy varies dramatically by business model and industry vertical. Content publishers, e-commerce platforms, SaaS companies, and documentation sites face fundamentally different trade-offs between AI visibility, server costs, intellectual property protection, and future agent-action revenue opportunities.
🎯 The Industry Differentiation Reality
A content publisher maximizing ad-supported traffic prioritizes entirely different crawler access than a SaaS company protecting proprietary documentation. E-commerce platforms preparing for agent-executed purchases require different technical infrastructure than thought leadership brands seeking maximum AI citation visibility.
"Blocking or allowing really depends on your goals."
— u/DataDriven_SEO, r/SEO
Traditional technical SEO provides generic crawler blocking templates without industry context, missing that optimal strategy for publishers (maximize AI search visibility) directly contradicts optimal strategy for proprietary platforms (control intellectual property access).
❌ The One-Size-Fits-All Template Trap
Legacy SEO agencies deliver identical robots.txt configurations regardless of client business model, applying cookie-cutter technical recommendations without strategic business analysis. They block GPTBot universally or allow everything indiscriminately, never asking: what does this crawler access pattern do to this specific company's revenue model?
The traditional approach treats all content as equivalent—blog posts receive the same crawler access policy as proprietary product documentation, missing the strategic differentiation opportunity between public thought leadership (maximize visibility) and competitive intelligence (protect access).
✅ Industry-Specific Strategic Frameworks
.png)
Content Publishers & Media Companies
Business Model: Ad-supported traffic, affiliate revenue, brand awareness
Optimal Strategy: Maximum AI search visibility
Crawler Access Matrix:
- ✅ Allow: PerplexityBot, ChatGPT-User, AI search crawlers (drive referral traffic)
- ✅ Allow: GPTBot, Google-Extended, CCBot (brand awareness through model training)
- ✅ Allow: Emerging crawlers (early mover advantage in new AI platforms)
- ❌ Block: Only confirmed malicious scrapers
Technical Priority: Schema optimization (Article, Author, Publisher schemas) ensuring maximum AI citation likelihood
Business Outcome: Referral traffic from AI search platforms, brand mentions in AI-generated content, early visibility advantage as AI search adoption grows
E-Commerce Platforms
Business Model: Product sales, conversion optimization
Optimal Strategy: Agent action readiness + selective training access
Crawler Access Matrix:
- ✅ Allow: AI search crawlers (product discovery in AI shopping assistants)
- ⚡ Rate Limit: Training crawlers (control server load from comprehensive product catalog crawls)
- ✅ Optimize For: Future agent-executed purchases (structured product + checkout metadata)
- ❌ Block: Aggressive scrapers stealing product data for competitors
Technical Priority: Product Schema, Offer Schema, and structured checkout pathway metadata enabling AI agents to complete purchases autonomously
Business Outcome: Product visibility in AI shopping recommendations, technical readiness for agent-driven transactions (the Blue Ocean opportunity)
SaaS Companies (Public Documentation)
Business Model: Lead generation, product education, community building
Optimal Strategy: Documentation discoverability + rate limiting
Crawler Access Matrix:
- ✅ Allow: AI search crawlers (developers researching solutions cite accessible docs)
- ✅ Allow: Training crawlers for public docs (AI models learn to recommend your product)
- ⚡ Rate Limit: Aggressive training crawlers (balance visibility with server costs)
- ❌ Block: Crawlers accessing authenticated areas
Technical Priority: FAQ Schema, How-To Schema, clear code example formatting for AI summarization
Business Outcome: Developer discovery through AI-assisted research, product citations in AI-generated technical recommendations
SaaS Companies (Proprietary/Enterprise)
Business Model: Enterprise contracts, competitive differentiation through IP
Optimal Strategy: Selective access control + IP protection
Crawler Access Matrix:
- ✅ Allow: Marketing content and public thought leadership to AI search crawlers
- ❌ Block: Product documentation, technical specifications, pricing details from training crawlers
- ❌ Block: Competitive intelligence gathering (feature comparisons, roadmaps)
- ✅ Protect: Customer portal and authenticated content completely
Technical Priority: Granular robots.txt + meta tag controls differentiating public vs. proprietary content areas
Business Outcome: Thought leadership visibility without competitive intelligence leakage, protected IP and pricing strategies
📊 Implementation Maturity Model: Progressive Evolution
Level 1: Basic (Foundational Control)
- Capabilities: robots.txt implementation, basic crawler awareness
- Tools: Standard robots.txt file, Google Search Console monitoring
- Business Fit: Small sites, limited technical resources
- Gaps: No compliance verification, reactive problem-solving
Level 2: Intermediate (Strategic Differentiation)
- Capabilities: Selective crawler access (allow search, control training), rate limiting, basic compliance monitoring
- Tools: robots.txt + meta tags, server-level rate limiting, log analysis
- Business Fit: Growing SaaS startups, content publishers, mid-market e-commerce
- Gains: Business-aligned crawler policies, server cost optimization
Level 3: Advanced (Business Outcome Optimization)
- Capabilities: Industry-optimized strategy, agent action readiness, continuous compliance monitoring, ROI measurement per crawler
- Tools: WAF rules, behavioral analysis, Schema optimization, referral tracking, enforcement escalation
- Business Fit: Enterprise SaaS, major publishers, e-commerce platforms
- Gains: Measured business outcomes, future-proofed infrastructure, competitive AI visibility advantage
🎯 Maturity Self-Assessment
Question 1: Do you know which specific AI crawlers access your site and their traffic volume?
- No = Level 1 | Basic awareness = Level 2 | Detailed tracking = Level 3
Question 2: Are crawler access policies aligned with your business model and revenue strategy?
- Generic template = Level 1 | Business-aware = Level 2 | ROI-optimized = Level 3
Question 3: Do you measure referral traffic and business outcomes per crawler?
- No measurement = Level 1 | Basic tracking = Level 2 | Revenue attribution = Level 3
Question 4: Is your technical infrastructure prepared for agent-executed transactions?
- Not considered = Level 1 | Awareness = Level 2 | Implemented = Level 3
💡 MaximusLabs' Industry-Optimized Approach
MaximusLabs doesn't deliver generic technical SEO templates—we implement industry-specific maturity acceleration. Our approach:
For Publishers: Maximize AI citation opportunities through comprehensive Schema implementation, allow-all crawler policies, and content formatting optimized for AI summarization
For E-Commerce: Prepare infrastructure for agent-executed purchases through Product/Offer Schema, structured checkout metadata, and selective crawler access balancing visibility with competitive protection
For SaaS: Differentiate public documentation (maximize discoverability) from proprietary content (protect IP), with technical architecture supporting both visibility and access control simultaneously
Maturity Evolution: Guide clients through appropriate implementation stages—Level 1 foundations for resource-constrained startups, Level 2 strategic differentiation for growth-stage companies, Level 3 outcome optimization for enterprises capturing AI search market share
This isn't one-size-fits-all technical SEO—it's business model-aligned crawler strategy with maturity-appropriate implementation, positioning clients to capture industry-specific AI visibility opportunities while avoiding generic template waste that characterizes legacy technical approaches.
Q9. Detection and Monitoring: Identifying AI Crawler Traffic in Your Server Logs [toc=Log Detection & Monitoring]
Effective AI crawler management requires continuous monitoring of actual bot behavior through server log analysis. Understanding which crawlers access your site, their traffic volume, and compliance with your access policies enables data-driven strategy adjustments.
📊 Step 1: Access Your Server Logs
Server logs record every request made to your website, including crawler user-agent strings, IP addresses, requested URLs, and timestamps.
Apache Server:
Access logs typically located at /var/log/apache2/access.log or /var/log/httpd/access_log
Nginx Server:
Default location: /var/log/nginx/access.log
Cloudflare Users:
Download logs via Cloudflare Dashboard → Analytics → Logs
Managed Hosting:
Access through cPanel, Plesk, or hosting control panel under "Raw Access Logs" or "Web Statistics"
🔍 Step 2: Identify AI Crawler User-Agents
Use command-line tools to filter log files for specific AI crawler user-agents.
Search for GPTBot:
bash
grep "GPTBot" /var/log/nginx/access.log
Check Multiple Crawlers:
bash
grep -E "GPTBot|Google-Extended|ClaudeBot|PerplexityBot|CCBot" /var/log/nginx/access.log
Count Requests Per Crawler:
bash
grep "GPTBot" access.log | wc -l
This reveals total request volume from specific crawlers over the log period.
📈 Step 3: Analyze Crawler Traffic Patterns
Calculate Traffic Percentage:
bash
# Total requests
wc -l access.log# GPTBot requests
grep "GPTBot" access.log | wc -l# Calculate percentage: (GPTBot requests / Total requests) × 100
"Do you have crawler analytics to see the impact of it? Blocking or allowing really depends on your goals."
— u/DataDriven_SEO, r/SEO
Identify Most Requested URLs:
bash
grep "GPTBot" access.log | awk '{print $7}' | sort | uniq -c | sort -rn | head -20
This shows which pages specific crawlers access most frequently, revealing content priorities.
Analyze Crawl Frequency:
bash
grep "GPTBot" access.log | awk '{print $4}' | cut -d: -f1-2 | uniq -c
Reveals requests per hour, identifying aggressive crawl patterns that may warrant rate limiting.
⚠️ Step 4: Detect robots.txt Violations
Compare Against robots.txt Rules:
If your robots.txt blocks GPTBot from /private/:
Any results indicate non-compliance requiring enforcement escalation (server-level blocks or WAF rules).
"Most LLMs seem to ignore robots.txt completely. I did test this."
— u/TechSEO_Discussion, r/TechSEO
🛠️ Step 5: Set Up Automated Monitoring
Google Analytics 4 (GA4):
Navigate to Reports → Tech → Traffic Acquisition → Add filter: Session source/medium contains bot or specific crawler names
Cloudflare Analytics:
Dashboard → Analytics → Traffic → Filter by bot traffic to see AI crawler request volumes and patterns
Log Analysis Tools:
- GoAccess (open-source): Real-time log analyzer with bot detection
- AWStats: Web analytics with bot identification
- Matomo: Privacy-focused analytics with crawler tracking
📋 Step 6: Create Crawler Monitoring Dashboard
Key Metrics to Track:
Weekly Monitoring Checklist:
- Review total crawler traffic percentage
- Identify new/unknown crawler user-agents
- Check robots.txt compliance violations
- Analyze referral traffic from citation crawlers (PerplexityBot)
- Adjust access policies based on business value vs. server cost
💡 MaximusLabs' Automated Crawler Intelligence
MaximusLabs AI eliminates manual log analysis complexity through automated crawler monitoring systems that continuously track AI bot behavior, detect compliance violations in real-time, and provide business outcome dashboards showing referral revenue per crawler—enabling data-driven access policy optimization without the technical overhead of manual log parsing and analysis.
Q10. The Technical Foundation: Why Schema, Clean HTML & JavaScript Optimization Matter for AI Crawler Access [toc=Technical Foundation]
The digital search landscape is experiencing a fundamental shift in how content discovery works. While traditional SEO focused on making websites visible to search engines like Google, the emergence of AI platforms—ChatGPT, Perplexity, Gemini, and Grok—demands a different technical foundation. AI crawler management isn't just about blocking bots; it's about ensuring the content you want discovered is accessible, parseable, and understandable through structured data that AI engines can confidently cite.
❌ The 95% Technical SEO Waste Problem
Traditional SEO agencies dedicate enormous resources to technical audits that drive minimal business impact. They perform comprehensive site crawls identifying hundreds of "issues"—duplicate meta descriptions, missing alt tags, broken internal links to low-value pages, minor mobile usability concerns—creating impressive-looking reports filled with work that produces zero revenue impact.
"Make sure your entire page is readable as HTML - AI crawlers currently cannot read JavaScript."
— u/WebDev_Insights, r/webdevelopment
Legacy technical SEO operates on outdated assumptions: optimizing for Googlebot's 2015 capabilities, pursuing PageSpeed scores for vanity metrics, and implementing generic "best practices" without AI context. The result? Organizations invest thousands in technical SEO work while missing the mission-critical 5% that actually determines AI crawler access and citation likelihood.
✅ The Mission-Critical 5%: AI Technical Requirements
AI platforms don't just crawl websites—they need to confidently extract structured facts to cite in responses. This requires three foundational technical elements that traditional SEO chronically underdelivers:
1. Comprehensive Schema Implementation: The AI Language
Schema markup is no longer decoration for rich snippets—it's the critical language for AI discoverability. When AI engines parse your content, Schema provides the structured facts they need to confidently cite your brand.
Essential Schema Types for AI Citation:
- Article Schema: Headline, author, publish date, article body structure
- Author Schema: Name, credentials, expertise, organizational affiliation
- Product Schema: Name, description, price, availability, reviews
- FAQ Schema: Question-answer pairs AI can directly extract
- Organization Schema: Company details, trust signals, official channels
Without comprehensive Schema, AI engines must interpret unstructured HTML—prone to errors and confidence penalties that reduce citation likelihood. Sites with complete Schema implementation provide machine-readable facts that AI platforms preferentially cite.
2. Clean HTML Accessibility: JavaScript Minimization
Not all AI crawlers process JavaScript effectively. While Googlebot renders JavaScript-heavy sites, many AI training crawlers (GPTBot, ClaudeBot) and search crawlers rely primarily on HTML content. If critical content or Schema markup requires JavaScript execution, many AI crawlers simply won't see it.
Critical HTML Accessibility Requirements:
- Primary content rendered in HTML, not JavaScript-dependent
- Schema markup in HTML
<script type="application/ld+json">tags, not dynamically generated - Headings, paragraphs, and structural elements in HTML, not client-side rendered
- Navigation and internal linking in crawlable HTML
<a>tags
The technical paradox: organizations spend resources building JavaScript-heavy interfaces for human users while inadvertently making content invisible to AI crawlers that determine brand visibility in the fastest-growing search channel.
3. Internal Cross-Linking Architecture: Crawler Discovery
AI crawlers discover content through links. Strong internal cross-linking accelerates bot crawl efficiency, helping crawlers discover high-value content faster and understand topical relationships.
High-Impact Linking Strategies:
- Link from high-authority pages (homepage, pillar content) to important articles
- Contextual links within content (not just footer/sidebar)
- Clear anchor text signaling topic relevance
- Reasonable link density (avoid link spam, focus on value)
🎯 MaximusLabs' Technical Trust Engineering
MaximusLabs implements Technical Trust Engineering that concentrates exclusively on the high-leverage 5% of technical work enabling AI crawler access and citation:
Schema-First Architecture: We implement comprehensive, accurate Schema across all content types—Article, Author, Product, Organization—providing the structured facts AI engines need for confident citation. This isn't checkbox Schema implementation; it's strategic markup aligned with how LLMs parse and extract information.
HTML Accessibility Guarantee: We audit and refine markup ensuring critical content and Schema are accessible in HTML, not JavaScript-dependent. This eliminates the risk of content invisibility to AI crawlers that don't process JavaScript effectively.
Crawl Efficiency Optimization: We architect internal linking that maximizes AI crawler discovery efficiency, helping bots find high-value content faster while understanding topical authority through contextual link relationships.
Zero Generic Audit Waste: We don't perform traditional technical SEO audits identifying hundreds of low-impact issues. Our focus: only the mission-critical technical elements that determine AI crawler access and citation likelihood—avoiding the 95% waste characterizing legacy technical SEO.
This isn't traditional technical SEO—it's AI-era technical infrastructure that validates E-E-A-T signals specifically for AI engines. Organizations that perfect these fundamentals capture AI search visibility advantages while competitors waste resources on generic audits that drive no business outcomes.
📈 The Technical Reality: Foundation Determines Visibility
The technical paradox is stark: 95% of traditional technical SEO work drives minimal impact, but the critical 5%—Schema, HTML accessibility, bot enablement—is mission-critical for LLM access. Sites missing this foundation simply aren't cited by AI platforms, regardless of content quality.
"Focus on structured data and clear, concise content for GEO."
— u/GEO_Strategist, r/bigseo
MaximusLabs focuses exclusively on this high-leverage work, making technical foundation the enabler of AI visibility rather than a compliance checkbox. Our Trust-First SEO methodology embeds technical trust signals into infrastructure—Schema as AI language, HTML as guaranteed access, cross-linking as discovery acceleration—positioning clients to win AI citations while competitors perform zero-impact legacy audits.
The shift from Google-only SEO to AI-native optimization requires technical foundations optimized for machine parsing and confident extraction. Organizations that perfect this critical 5% capture defensible AI visibility advantages as over 50% of search traffic migrates to AI platforms by 2028.
Q11. Preparing for the Future: Agent Action Optimization, Pay-Per-Crawl Models & AI Authentication [toc=Future Trends]
The evolution of AI crawlers extends far beyond content scraping for training data or real-time query responses. The next frontier involves autonomous AI agents performing on-site actions—booking hotels, purchasing products, completing forms—on behalf of users, fundamentally transforming how conversion happens online.
🚀 The Agent Action Revolution
AI platforms are rapidly evolving from answering questions to executing tasks. ChatGPT, Perplexity, and similar tools increasingly function as users' Executive Assistants, completing complex multi-step processes: researching products, comparing options, and ultimately executing transactions without human intervention for each step.
This represents a massive market opportunity: AI-driven conversions from highly qualified users who've already decided to act, delegating execution to their AI assistant. Sites technically prepared for agent-executed actions capture this Blue Ocean revenue stream; sites optimized only for human interaction miss it entirely.
❌ The Traditional Agency Blindspot
Legacy SEO agencies remain laser-focused on the Red Ocean of content optimization—fighting for Google rankings alongside thousands of competitors using identical strategies. They completely miss the emerging Blue Ocean of Agent Action Optimization—a category boundary most competitors haven't even recognized exists.
"Plan and optimize before starting. Clearly define your goals and the scope."
— u/Crawler_Strategist, r/webdevelopment
Traditional agencies optimize for human clicks and conversions, implementing conversion rate optimization tactics designed for human decision-making. They don't consider: Can an AI agent successfully navigate our checkout process? Is product availability structured for machine parsing? Can a bot execute a booking without JavaScript-dependent interactions?
The result: organizations invest heavily in human-focused conversion optimization while their technical infrastructure actively prevents the next generation of highly qualified, agent-driven conversions.
✅ Emerging Trends Reshaping AI Crawler Economics
1. Agent Action Requirements: The Technical Imperative
AI agents acting as Executive Assistants need structured information about buttons, forms, and conversion pathways—metadata describing how to interact with site elements to execute user tasks.
Technical Requirements for Agent-Executable Actions:
- Button Metadata: Structured descriptions of button functions (
aria-label, Schema Action markup) - Form Structure: Machine-readable form fields with clear input expectations
- Conversion Pathway Markup: Structured data describing checkout/booking processes
- Error Handling: Clear, parseable error messages enabling bot troubleshooting
- State Management: API endpoints or structured updates enabling bots to track process completion
Sites implementing this infrastructure enable AI agents to complete transactions autonomously, capturing revenue from users who've delegated execution to their AI assistant.
2. Pay-Per-Crawl Models: Monetizing AI Access
Cloudflare recently introduced pay-per-crawl models where AI training companies pay content owners for crawler access—fundamentally restructuring the economics of AI bot management.
The New Economic Reality:
- Traditional Model: AI companies crawl freely, extracting value without compensation
- Pay-Per-Crawl Model: Content owners monetize their data, receiving payment for AI training access
- Strategic Implication: Blocking all training bots may mean missing monetization opportunities; allowing all means undervaluing your content
Organizations need strategies evaluating: Which training crawlers provide referral value vs. which should pay for access? How does pay-per-crawl revenue compare to AI citation benefits?
3. AI Crawler Authentication Protocols: Trusted Ecosystems
Emerging authentication protocols aim to create verified crawler ecosystems where bots prove identity and purpose, enabling content owners to grant differentiated access based on verified crawler behavior and business relationships.
Authentication Benefits:
- Verified Identity: Confirm bot claims match actual behavior (eliminate user-agent spoofing)
- Access Contracts: Formal agreements specifying crawl limits, attribution requirements, payment terms
- Compliance Enforcement: Revoke access for bots violating agreements
- Trusted Relationships: Differentiated access for commercial partners vs. unknown crawlers
This structures the "wild west" of AI bot access into manageable, economically rational relationships.
4. Standardization Efforts: Structured Bot Management
Industry consortiums are developing standardized protocols (beyond simple robots.txt) for AI crawler management, including:
- Enhanced robots.txt directives specific to AI use cases
- Crawler certification programs verifying ethical behavior
- Attribution standards requiring AI platforms to cite sources
- Crawl transparency logs showing how content was used
🎯 MaximusLabs' Future-Readiness Strategy
MaximusLabs positions as strategic partner for organizations preparing to capture the next wave of AI-driven opportunities:
Agent Action Optimization Implementation: We structure button and form data, conversion pathway metadata, and technical infrastructure enabling AI agents to execute late-stage conversions—capturing highly qualified, agent-driven revenue that competitors' human-only optimization misses.
Pay-Per-Crawl Strategy Consulting: We advise organizations on evaluating pay-per-crawl economics—which training crawlers warrant free access (citation benefits) vs. which should pay (pure data extraction)—optimizing the business value equation.
Authentication Protocol Adoption: We implement emerging authentication standards positioning clients as early adopters in trusted crawler ecosystems, gaining first-mover advantages in AI platform partnerships.
Proactive Infrastructure Preparation: We don't wait for these trends to mature—we implement foundational infrastructure now that supports future capabilities, avoiding expensive retrofitting when agent actions become mainstream.
This isn't reactive technical SEO—it's strategic infrastructure positioning for the agent-action era. Organizations that prepare now capture defensible competitive advantages when AI-driven conversions become the dominant channel.
📈 The Strategic Opportunity
Agent Action Optimization represents high-value technical work with minimal competition—most organizations haven't recognized this category exists. Early movers capture:
- First-mover revenue: Agent-driven conversions from highly qualified users
- Partnership advantages: Preferred relationships with AI platforms seeking agent-enabled sites
- Technical differentiation: Infrastructure competitors can't quickly replicate
- Monetization optionality: Choice to participate in pay-per-crawl or pursue citation strategies
"If you want traffic, let people access your site. AI search is only going to increase."
— u/Traffic_Strategist, r/bigseo
MaximusLabs helps organizations future-proof AI infrastructure while competitors remain focused on legacy optimization—positioning clients to capture the shift from human clicks to autonomous agent transactions as AI platforms evolve from answering questions to executing user tasks.
Q12. Implementation Checklist: Your Step-by-Step AI Crawler Management Action Plan [toc=Implementation Checklist]
This comprehensive checklist organizes all AI crawler management recommendations into prioritized, actionable steps from immediate implementation to long-term strategic preparation.
🎯 Phase 1: Immediate Actions (Week 1)
Establish Baseline Understanding
✅ Audit Current Crawler Access
- Review existing robots.txt file at
yoursite.com/robots.txt - Document current AI crawler allow/block directives
- Identify if you're blocking unknown crawlers by default
✅ Analyze Server Logs
- Access server logs (Apache, Nginx, or hosting control panel)
- Search for AI crawler user-agents: GPTBot, Google-Extended, ClaudeBot, CCBot, PerplexityBot
- Calculate current AI crawler traffic percentage vs. total traffic
✅ Identify Business Model Fit
- Determine your industry vertical: Publisher, E-commerce, SaaS, Documentation
- Define strategic priority: Maximum visibility, selective control, or IP protection
- Assess current referral traffic from AI platforms (if any)
Implement Foundation Controls
✅ Configure Strategic robots.txt
- Allow high-value citation crawlers: PerplexityBot, ChatGPT-User
- Decide on training bot strategy (GPTBot, Google-Extended, ClaudeBot): allow, block, or selective paths
- Block confirmed low-value/non-compliant crawlers
- Save and test robots.txt using validation tools
✅ Set Up Basic Monitoring
- Configure Google Analytics or alternative to track bot traffic
- Create weekly log analysis schedule
- Document baseline metrics (crawler traffic %, requests per crawler)
📊 Phase 2: Strategic Optimization (Weeks 2-4)
Enhance Technical Foundation
✅ Implement Comprehensive Schema Markup
- Add Article Schema to all blog posts and articles
- Implement Author Schema with credentials and expertise
- Add Product Schema for e-commerce (including price, availability, reviews)
- Include FAQ Schema for common question-answer content
- Implement Organization Schema for company trust signals
✅ Audit HTML Accessibility
- Verify primary content renders in HTML (not JavaScript-dependent)
- Ensure Schema markup in HTML
<script>tags, not dynamically generated - Test content visibility with JavaScript disabled
- Fix critical content requiring JavaScript for AI crawler access
✅ Optimize Internal Linking
- Add contextual links from high-authority pages to important content
- Implement clear, descriptive anchor text
- Create pillar content with extensive internal linking to related articles
- Audit and fix broken internal links
Implement Advanced Controls
✅ Deploy Rate Limiting
- Configure server-level or WAF rate limiting for aggressive crawlers
- Set appropriate limits: 5-10 requests per minute for training bots, higher for search bots
- Monitor rate limit trigger frequency
✅ Add Meta Tag Controls
- Implement
noai, noimageaimeta tags for sensitive content - Add crawler-specific meta tags for granular page-level control
- Document which content types use which meta tag strategies
🔍 Phase 3: Compliance Verification (Month 2)
Test Crawler Compliance
✅ Verify robots.txt Respect
- Monitor server logs for 30 days post-robots.txt implementation
- Identify crawlers accessing blocked paths (compliance violations)
- Document non-compliant crawlers for enforcement escalation
✅ Implement Enforcement Escalation
- Add user-agent filtering (Apache .htaccess or Nginx) for documented violators
- Configure WAF rules for persistent non-compliant bots
- Consider IP blocking for severe violation patterns
✅ Measure Business Outcomes
- Track referral traffic from PerplexityBot and other citation crawlers
- Calculate server cost per referral visitor
- Adjust access policies based on measured ROI per crawler
💡 Phase 4: Strategic Maturity (Months 3-6)
Industry-Specific Optimization
✅ Tailor Strategy to Business Model
- Publishers: Maximize AI search visibility, allow all citation crawlers, optimize for AI summarization
- E-commerce: Implement Product Schema, prepare for agent actions, rate limit training bots
- SaaS: Differentiate public docs (allow) vs. proprietary content (block), optimize for developer discovery
- Proprietary Platforms: Protect competitive intelligence, allow selective marketing content
✅ Advance Maturity Level
- Level 1 → 2: Add compliance monitoring, selective crawler access, basic outcome tracking
- Level 2 → 3: Implement ROI measurement per crawler, agent readiness, industry-optimized strategy
✅ Prepare for Agent Actions
- Add button metadata and form structure for bot interaction
- Implement conversion pathway markup
- Test checkout/booking process with automated tools
- Document agent-executable workflows
🚀 Phase 5: Future-Proofing (Ongoing)
Monitor Emerging Trends
✅ Stay Updated on New Crawlers
- Monitor server logs weekly for unknown user-agents
- Research new AI crawler announcements (OpenAI, Anthropic, Google, emerging platforms)
- Test new crawler compliance with robots.txt
✅ Evaluate Pay-Per-Crawl Opportunities
- Monitor Cloudflare and similar platforms for monetization programs
- Calculate potential revenue from training bot access
- Assess pay-per-crawl vs. citation visibility trade-offs
✅ Adopt Authentication Protocols
- Monitor industry standardization efforts
- Implement authentication protocols as they mature
- Join early adopter programs for AI platform partnerships
Continuous Optimization
✅ Monthly Review Cycle
- Analyze crawler traffic trends and patterns
- Review compliance violations and enforcement effectiveness
- Measure referral revenue per crawler
- Adjust access policies based on business outcomes
✅ Quarterly Strategic Assessment
- Reassess business model fit and crawler strategy alignment
- Evaluate new technical capabilities (agent readiness, Schema coverage)
- Update implementation maturity level
- Set next-quarter strategic priorities
📋 Quick Reference: Priority Matrix
🎯 How MaximusLabs Accelerates Implementation
MaximusLabs AI simplifies this multi-phase implementation journey through end-to-end Technical Trust Engineering that handles strategy development, technical implementation, compliance monitoring, and continuous optimization—positioning organizations to capture AI search opportunities without the internal resource burden of managing complex, evolving crawler ecosystems across technical, strategic, and business outcome dimensions simultaneously.
.png)

.png)
